A/B Testing Lead Generation Campaigns: 2026 Playbook
Most lead gen A/B tests fail because of bad math, not bad creative. Here's how to design tests that actually move pipeline in 2026.

TL;DR#
- Most lead generation A/B tests are underpowered, undersized, and called too early — you need at least a few hundred conversions per variant to trust the result.
- Test one variable at a time at the top of funnel (subject lines, hero copy, CTA), then graduate to multivariate tests at the bottom (forms, offers, pricing).
- A 10% lift in form conversion is realistic. A 200% lift is almost always measurement error or selection bias.
- The math matters more than the creative: bake significance, MDE, and sample size into the test plan before you launch.
- Pair quantitative A/B data with qualitative signals (session recordings, sales call notes) so you don't optimize the wrong metric.
What is A/B testing in lead generation?#
A/B testing in lead generation is the practice of running two or more versions of a marketing asset — a landing page, an ad, a cold email, a form — against the same audience to see which one produces more qualified leads at a lower cost. Half the traffic sees variant A (the control), half sees variant B (the challenger). Whichever variant moves the metric you actually care about — booked meetings, MQLs, pipeline — wins.
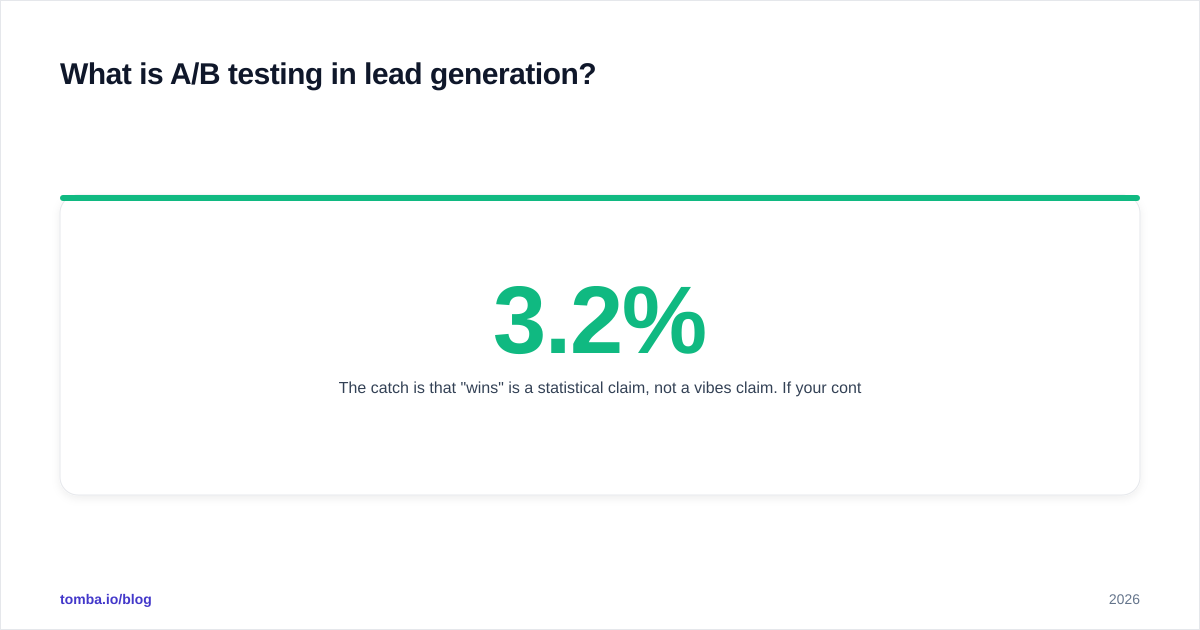
The catch is that "wins" is a statistical claim, not a vibes claim. If your control converts at 3.2% and your challenger converts at 3.6% off 400 visitors each, you do not have a winner — you have noise. A b testing lead generation campaigns is one of the highest-leverage activities in B2B marketing, but only if you respect the math.

Done well, A/B testing turns guesswork into a compounding flywheel: each validated experiment becomes the new control, each new control raises the floor, and over 12 months you end up with a funnel that converts 2–4x better than the one you started with. Done badly, it produces "wins" that vanish the moment you turn the test off.
Why do most lead generation A/B tests fail?#
Five reasons account for roughly 90% of failed experiments:
- Too little traffic. Teams test on 200 sessions per variant when they need 4,000. Anything below the minimum detectable effect (MDE) is statistical static.
- Peeking and stopping early. Watching the dashboard every hour and calling it the moment p < 0.05 inflates false positives by 3–5x.
- Testing the wrong thing. Changing the button color when the offer is the bottleneck. A 0.4% lift on a $50K problem is rounding error.
- Wrong success metric. Optimizing for form fills when sales close rate craters because you watered down the qualification copy.
- Selection bias. Running an A/B test on a paid campaign while organic traffic shifts in the background, contaminating both arms.
The fix is process, not cleverness. Write the hypothesis, calculate sample size, commit to a stop date, define the metric, and only then design the creative.

How do you design a statistically sound test?#
A useful template for any lead generation experiment has five parts:
- Hypothesis. "Replacing the generic hero with a vertical-specific value prop will increase demo-request conversion from 2.8% to 3.6%." Specific, falsifiable, tied to a number.
- Primary metric. One metric, picked before launch. Pipeline-adjacent is better than top-of-funnel — booked meetings beats raw form fills.
- Minimum detectable effect (MDE). The smallest lift you actually care about. A 5% relative lift requires roughly 4x the sample size of a 10% lift, so be honest.
- Sample size calculation. Use a calculator (Evan Miller, Optimizely, VWO) with your baseline rate, MDE, and 80% power at 95% confidence.
- Stop date or stop sample. Decide upfront when the test ends. Stop early only if you cross a pre-registered futility threshold.
Bake those five into a one-page test brief before a single pixel moves. If the brief says "we need 12,000 visitors and we get 800 a week," you know upfront that the test will take 15 weeks — and you can decide whether the question is worth that runway.
What should you actually test in a B2B funnel?#
The ROI of an A/B test scales with how close to the money the test sits. A subject line test on a 5,000-recipient cold campaign costs nothing and might lift replies 30%. A pricing page test where every win compounds across every paying customer for the next two years is even better. Button color changes are a distant last.
Prioritize tests in this order:
| Funnel stage | High-leverage tests | Realistic lift | Sample size hint |
|---|---|---|---|
| Cold outreach | Subject line, opener, offer, CTA placement | 15–40% on reply rate | 1,000+ sends per variant |
| Paid ads | Hook, headline, creative format, audience | 10–30% on CTR / CPL | 500+ clicks per variant |
| Landing page | Hero, social proof, form length, offer | 10–25% on conversion | 2,000+ visitors per variant |
| Form / signup | Field count, multi-step, autofill, friction | 5–20% on completion | 1,500+ form views per variant |
| Pricing / demo page | Plan layout, anchor pricing, CTA copy | 5–15% on demo requests | 3,000+ visitors per variant |
| Nurture email | Subject, send time, length, CTA | 5–15% on click rate | 800+ sends per variant |
Notice the lifts get smaller as you move down the funnel — that's expected. The deeper visitors are in the funnel, the more pre-qualified they already are, and the harder it is to move them with copy alone. That's fine. A 7% lift on a pricing page that sees 50K visits a year compounds harder than a 30% lift on a cold email blast that runs for two weeks.

How big does the test sample need to be?#
This is where most teams blow themselves up. The rule of thumb most marketers carry around — "you need at least 100 conversions per variant" — is wrong by an order of magnitude for the lifts they're chasing.
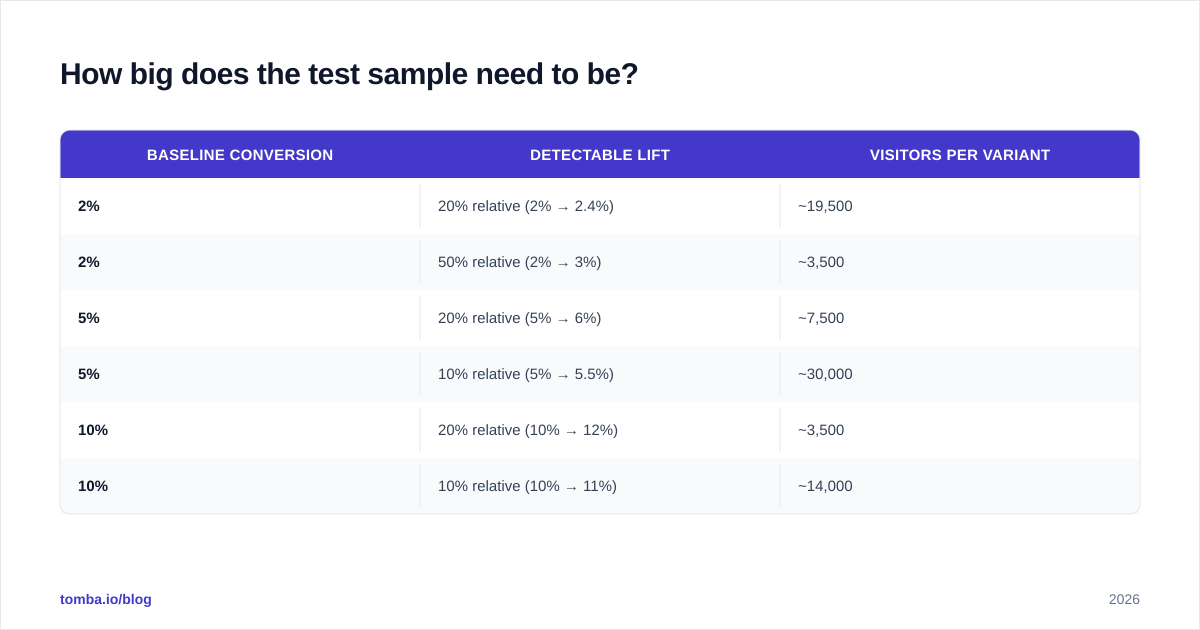
Quick reference for a two-sided test at 95% confidence and 80% power:
| Baseline conversion | Detectable lift | Visitors per variant |
|---|---|---|
| 2% | 20% relative (2% → 2.4%) | ~19,500 |
| 2% | 50% relative (2% → 3%) | ~3,500 |
| 5% | 20% relative (5% → 6%) | ~7,500 |
| 5% | 10% relative (5% → 5.5%) | ~30,000 |
| 10% | 20% relative (10% → 12%) | ~3,500 |
| 10% | 10% relative (10% → 11%) | ~14,000 |
Two things jump out. First, small absolute lifts on small baselines need enormous samples. Second, doubling the lift you require quarters the sample size — which is why MDE is the single most important number in your test plan.
If your traffic is too thin for a fair test, you have three options: run the test longer (months, not weeks), test higher in the funnel where volume is bigger, or test bigger creative swings where the MDE is realistically larger.
How long should an A/B test run?#
Long enough to capture at least one full business cycle. For B2B that means a minimum of two full weeks even if your sample calculator says you hit significance on day 4. Monday traffic does not behave like Friday traffic. Mid-month buyers do not behave like end-of-quarter buyers. EU traffic does not behave like APAC traffic.
A reasonable default:
- Minimum 14 days to cover weekly cycles.
- Maximum 6 weeks before external factors (seasonality, competitor moves, ad fatigue) corrupt the test.
- No peeking before day 7. Set a calendar reminder; close the dashboard.
- One full purchase cycle when the metric is downstream of the form fill (e.g., closed-won pipeline).
If you genuinely cannot generate enough traffic in 6 weeks, the test is the wrong test. Either lower your confidence threshold (90% is fine for directional reads), pick a higher-volume page, or accept that this question can't be answered with A/B testing and use qualitative research instead.
What tools do you actually need?#
Most B2B teams over-tool A/B testing. You need four things, and most teams already have three of them.
| Tool category | What it does | Common picks | Notes |
|---|---|---|---|
| Experimentation platform | Splits traffic, computes stats | VWO, Optimizely, Convert, GrowthBook | Open-source GrowthBook is fine to start |
| Analytics | Confirms downstream metrics | GA4, Mixpanel, PostHog | A/B tool ≠ source of truth |
| Lead source enrichment | Tells you who actually converted | Tomba, Clearbit, |
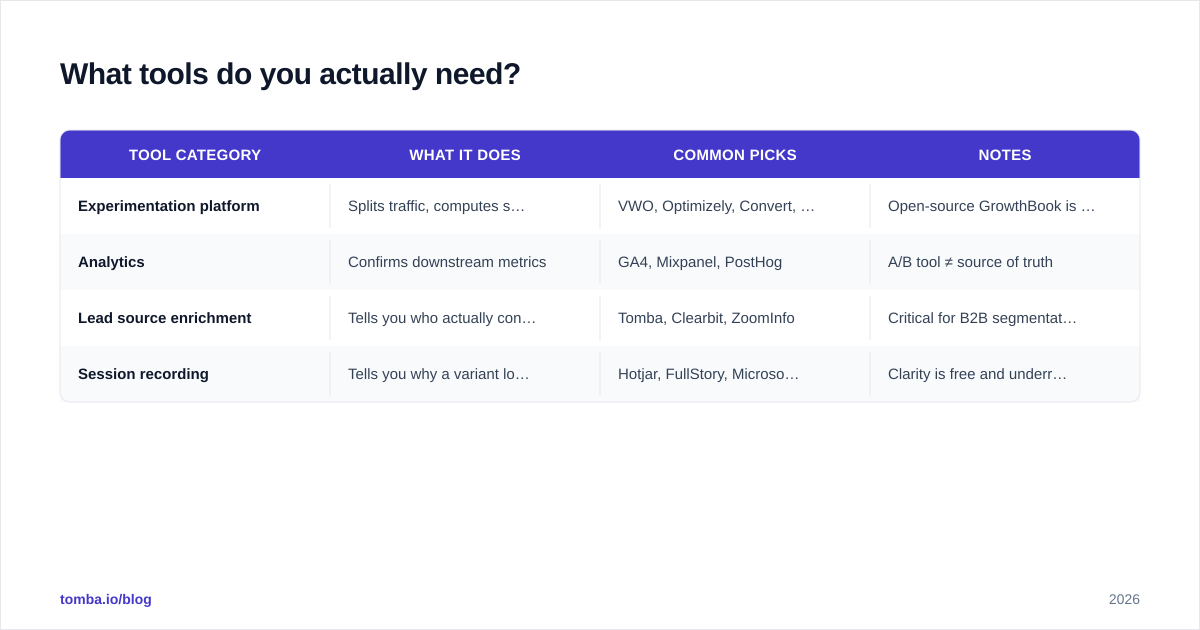
ZoomInfo | Critical for B2B segmentation | | Session recording | Tells you why a variant lost | Hotjar, FullStory, Microsoft Clarity | Clarity is free and underrated |
The non-obvious piece is lead enrichment. A landing page test that "wins" by attracting 2x more form fills from solopreneurs in a market where you sell to mid-market RevOps teams is not a win — it's a loss disguised as a win. Enriching every captured lead with firmographics (employee count, industry, tech stack) at the moment of capture lets you score variants on lead quality, not lead quantity. A solid email finder, verifier, and enrichment stack — Tomba's Email Finder and data enrichment cover this end-to-end — closes that loop without bolting on three separate vendors.
What are the most common mistakes that ruin A/B tests?#
The same patterns kill experiments in company after company. If you read nothing else, internalize these.
Calling tests early. Sequential peeking inflates false-positive rates dramatically. If you must look daily, use a sequential testing method (mSPRT, group sequential, Bayesian) that adjusts for it.
Treating p < 0.05 as binary. A test with p = 0.049 is not meaningfully different from one with p = 0.051. Look at effect size and confidence intervals together, not the magic number.
Ignoring novelty effects. A flashy new variant gets a click-rate boost in week 1 that vanishes by week 4. Run long enough that novelty washes out.
Optimizing the wrong funnel stage. Lifting form fills 30% while close rate drops 50% is a pyrrhic victory. Always validate downstream — pipeline, not pageviews.
Skipping segmentation. A variant that loses overall might be a giant win for your ICP segment and a giant loss for tire-kickers. Pre-register two or three segments in the test plan, not 17 post-hoc.
Not documenting losses. Every losing test teaches you the boundary of what works. Keep a registry. Six months in, the registry is worth more than any individual win.

How does lead data quality affect A/B test outcomes?#
A surprising amount. The signal you're measuring assumes the leads you capture are real, reachable, and roughly the right profile. If 30% of submitted emails are typos, freemail addresses, or role-based (info@, sales@), you're not measuring "did the variant convert better" — you're measuring "did the variant attract more junk."
Two practical interventions:
- Verify at submit. Run every email through email verification at the point of capture. Variants that "win" by attracting more bounces are demoted automatically.
- Enrich at submit. Append firmographic data — company size, industry, role — to every lead in real time. Now your A/B test result can be sliced by ICP fit, not just raw count.
A two-variant landing page test where variant B captured 18% more leads can look very different once you enrich: maybe variant A captured 22% more ICP-fit leads, and variant B's lift came from out-of-market traffic. Without enrichment, you'd have shipped the wrong winner.
If you're using LinkedIn-sourced traffic in the test, a LinkedIn finder helps you backfill profile data from email captures so you can attribute lift cleanly across persona segments.
How do you build an experimentation culture?#
Tools and statistics get you maybe halfway there. The other half is operational:
- Public test registry. A shared doc (Notion, Linear, GitHub) where every test lives: hypothesis, MDE, sample size, dates, outcome, learning. Anyone in the company can read it.
- Weekly review. 30 minutes, all in-flight tests, no surprises. Saves you from finding out three months later that two teams ran conflicting tests on the same page.
- Pre-mortems. Before a test launches, the team writes down what they expect to see and why. Calibration training. Within a year, intuitions sharpen dramatically.
- Test budget. Reserve 20% of campaign capacity for experiments. Otherwise the team always optimizes the current quarter and never invests in the next one.
- One owner per test. Group ownership produces orphaned tests. Designate a directly responsible individual.
The cultural shift is moving from "we think this will work" to "we'll know in three weeks." When that shift sticks, leadership stops vetoing test ideas based on taste and starts vetoing them based on cost/runway. That's when compounding starts.
How does A/B testing connect to the rest of the GTM stack?#
A/B testing in lead generation is one input into a broader revenue operations stack. The winners flow into your CRM, the losers flow into your learnings doc, and the leads themselves flow into outbound, nurture, and sales.
Common integrations worth investing in:
- CRM — every captured lead tagged with the test ID and variant ID so revenue can be attributed back (HubSpot integration, Salesforce integration).
- Email verifier — gate every submit through email verification before it reaches the CRM, so bad data never pollutes the test result.
- Enrichment API — hit a Tomba API call on every submit to append firmographics in real time.
- Sequencer / cold email tool — route variant-A leads and variant-B leads into the same nurture so you're not introducing a second variable downstream.
For broader benchmarks on how A/B testing fits inside the larger conversion-rate-optimization landscape, the HubSpot CRO research and the G2 CRO software grid are good external references. For statistical primers without the marketing-vendor spin, the Wikipedia entry on A/B testing is short and accurate.
What does a 90-day experimentation roadmap look like?#
If you're starting from zero, here's a realistic plan.
Days 1–14. Audit. Where does traffic enter? What's the conversion rate at each step? Where are the high-leverage choke points? Pick three.
Days 15–30. Tool setup. Wire up the experimentation platform, define the primary metric in analytics, set up lead verification and enrichment at submit. Write the test brief template.
Days 31–60. Run your first two tests. Big swings, not button colors. Hero rewrites, offer changes, audience shifts. Document everything — wins and losses.
Days 61–90. Cadence. Three tests in flight at a time. Weekly review. Public registry updated after every test concludes. Start training a junior team member to run tests independently.
By month four you should have 8–12 completed tests in the registry, a clear sense of which levers move your funnel, and a defensible argument for the experimentation budget next year.
Try Tomba for your lead generation tests#
Reliable A/B tests need reliable lead data — verified emails, enriched profiles, and clean segmentation. Tomba's Email Finder plugs into your landing page submits, paid funnels, and outbound tests so you can score variants on ICP-fit leads rather than raw form counts. Start on the free tier (25 searches/month), then graduate to the $49/mo Starter plan when your test volume picks up — see Tomba pricing for the full breakdown. Pair it with the email verifier at submit and the data enrichment endpoint at handoff, and every test you run will tell you something true.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author