How to A/B Test Email Variations in 2026: A Practical Guide
Most A/B tests on cold email are statistical noise. Here's how to design tests that actually move reply rates in 2026 — sample sizes, variables, and the math behind real winners.

How to A/B Test Email Variations in 2026: A Practical Guide
TL;DR
- Most cold-email A/B tests are underpowered — 200 sends per variant is rarely enough to detect anything smaller than a 10-point lift.
- Test one variable at a time, and prioritize variables in this order: audience, offer, subject line, opener, CTA, send time.
- Reply rate is the only metric worth optimizing in 2026. Open rate is broken thanks to Apple MPP and Gmail prefetching.
- Use a one-tailed two-proportion z-test, p < 0.05, and a minimum detectable effect (MDE) you set before you launch.
- Stop "winning" tests early. Sequential peeking is how teams trick themselves into rolling out worse copy.
If you have ever shipped two subject lines, watched one pull 32% replies and the other 28%, and declared a winner — this guide is for you. The math says you probably did not have a winner. You had noise.
This is a working playbook for how to ab test email variations in cold outbound, drip campaigns, and lifecycle email. It covers what to test, how big the test needs to be, which tools handle the mechanics, and the statistical traps that quietly poison most experiments.
What does it mean to A/B test email variations?#
An A/B test on email is a controlled experiment. You split a population randomly into two (or more) groups. Each group receives a different version of the same email. After the campaign sends, you compare a primary metric — reply rate, meeting-booked rate, click-through rate — and decide which version performed better.
The word "controlled" matters. If group A gets sent on Tuesday morning and group B gets sent Wednesday afternoon, you are not testing copy — you are testing send time mixed with copy. Most "A/B tests" in cold email tools are actually broken in exactly this way.
Real A/B tests share three properties:
- Random assignment. Every recipient has an equal chance of landing in each variant.
- Single variable. Only one thing differs between A and B. Everything else is identical.
- Predetermined sample size. You decide how many sends each variant needs before you launch, based on the effect size you want to detect.
If any of those three are missing, you have a marketing demo, not an experiment.

Which email variables are worth A/B testing?#
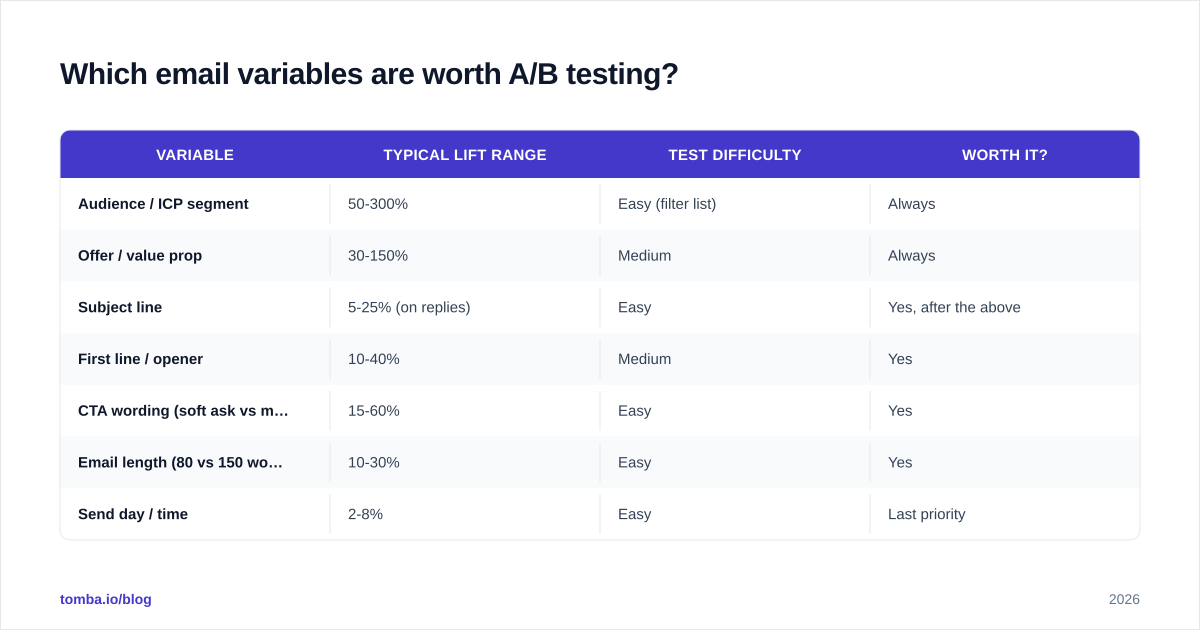
Not all variables are created equal. Some shift reply rates by 5 to 15 points. Others move the needle by 0.3. Spend your test budget on the high-leverage ones.
| Variable | Typical lift range | Test difficulty | Worth it? |
|---|---|---|---|
| Audience / ICP segment | 50-300% | Easy (filter list) | Always |
| Offer / value prop | 30-150% | Medium | Always |
| Subject line | 5-25% (on replies) | Easy | Yes, after the above |
| First line / opener | 10-40% | Medium | Yes |
| CTA wording (soft ask vs meeting ask) | 15-60% | Easy | Yes |
| Email length (80 vs 150 words) | 10-30% | Easy | Yes |
| Send day / time | 2-8% | Easy | Last priority |
| Sender name format | 3-10% | Easy | Last priority |
| HTML vs plain text | 5-15% (on deliverability) | Hard | Once, not per campaign |
The order is deliberate. If your ICP is wrong, no subject line can save the campaign. If your offer does not resonate, the CTA is decoration. Work top-down.
A second principle: test things you can act on. "Tuesday at 10am outperforms Wednesday at 2pm" is a finding that decays the moment your prospects' calendars change. "Engineers reply 3x more to a problem-led opener than a flattery opener" is a finding you can apply for years.

How many sends do you need per variant?#
This is the question that breaks every email test. The answer is almost always "more than you think."
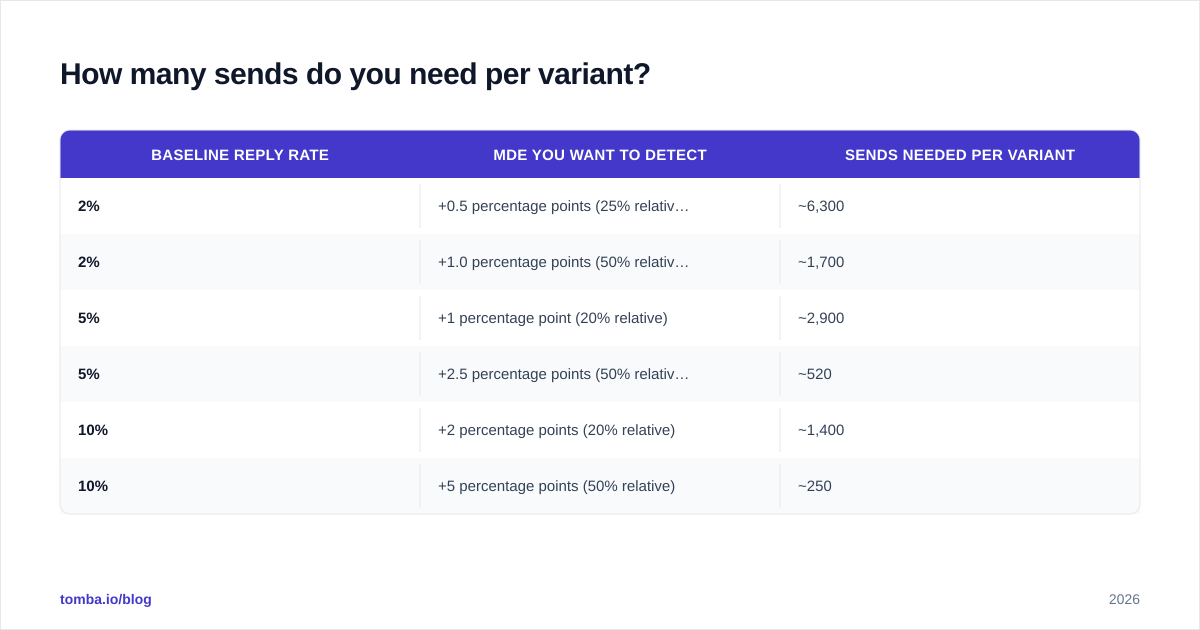
The math is a two-proportion z-test. Given a baseline reply rate, a minimum detectable effect (MDE), and the standard 95% confidence / 80% power thresholds, the formula returns a required sample size per variant.
| Baseline reply rate | MDE you want to detect | Sends needed per variant |
|---|---|---|
| 2% | +0.5 percentage points (25% relative) | ~6,300 |
| 2% | +1.0 percentage points (50% relative) | ~1,700 |
| 5% | +1 percentage point (20% relative) | ~2,900 |
| 5% | +2.5 percentage points (50% relative) | ~520 |
| 10% | +2 percentage points (20% relative) | ~1,400 |
| 10% | +5 percentage points (50% relative) | ~250 |
Most outbound teams send 500 leads into a sequence and call the test. At a 5% reply rate, 500 sends can reliably detect only enormous swings — roughly +5 points or more. Anything subtler is buried in noise.
Three implications:
- If your list is small, test bigger changes. Comparing two near-identical subject lines on 300 prospects is wasted effort.
- If you must test subtle changes, accumulate sends across multiple cohorts before calling the result.
- Stop running 4-variant tests with the same population you would use for a 2-variant test. You have just halved your statistical power per arm.
A practical heuristic: if you do not have at least 1,000 sends per variant and you are testing copy, expect noise to dominate signal.
How do you actually run the test without contaminating it?#
The mechanics matter as much as the math.
Randomize at the contact level, not the campaign level. If you create two campaigns ("Campaign A — Subject 1" and "Campaign B — Subject 2") and split your list manually, you have introduced two risks: list ordering bias (alphabetical, recency, or import order can correlate with company size, industry, or seniority), and timing skew (the two campaigns rarely send identically).
The right setup: one campaign, with a built-in 50/50 split that randomly assigns each contact to a variant at send time. Most modern sequencers — Instantly, Smartlead, Lemlist, Apollo, Outreach — support this. Use it.
Hold the send window constant. Both variants should send in the same hour, on the same day, from the same mailbox pool. If variant A goes from a freshly warmed inbox and variant B goes from one that is two weeks old, you are confounding copy with sender reputation.
Hold the follow-up sequence constant during the test. Only the email you are testing should differ. Follow-ups should be identical for both arms, otherwise the "winner" of step 1 might just be inheriting the better step 2.
Pre-register the metric. Decide before launching what metric counts and at what cutoff. "Reply rate at 14 days from send" is a clean spec. "Whatever looks good when I check on Tuesday" is not.
For finding the contacts in the first place, a reliable email finder keeps your list quality consistent across both variants — bad data inflates bounce rates and skews results.
Why is reply rate the only metric that matters in 2026?#
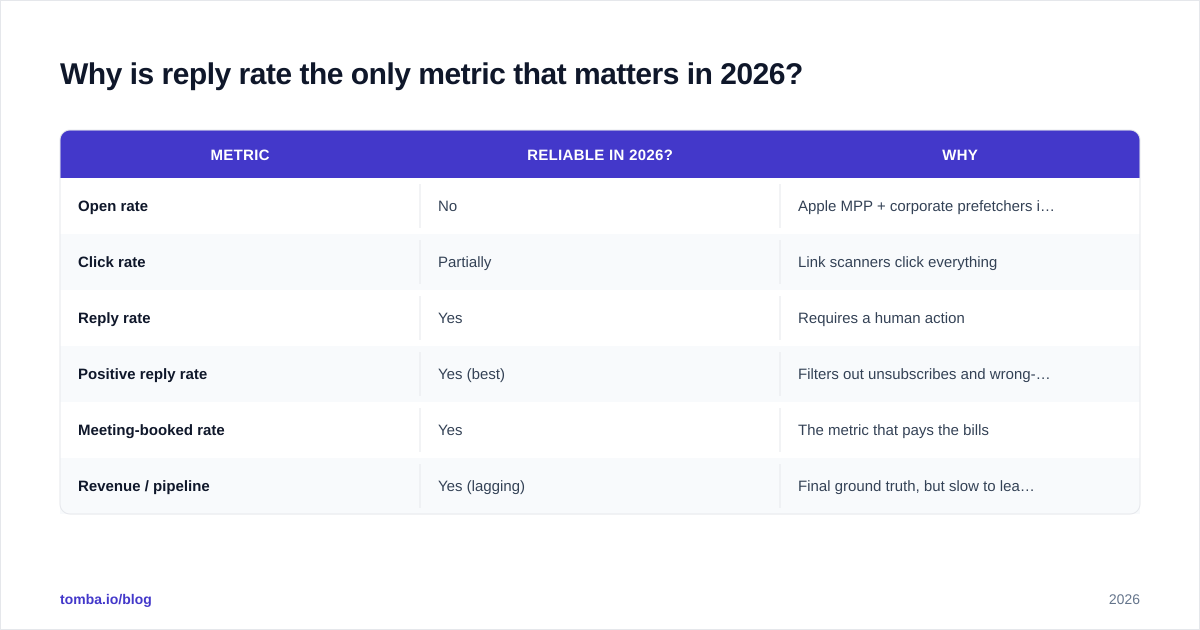
Open rate as a metric died in 2021 when Apple's Mail Privacy Protection started pre-fetching tracking pixels regardless of whether the user opened the email. Gmail's image proxying makes things worse. In 2026, a 70% "open rate" on a B2B campaign is meaningless — most of those opens are bots, prefetchers, and security scanners.
Click rate is better but still polluted, because corporate link-scanners (Mimecast, Proofpoint, Microsoft Safe Links) click every URL before the human ever sees the email. Some of those scanners click through to your landing page and trigger downstream conversion events.
Reply rate is what survives. A reply requires a human keystroke. It is downstream enough to be expensive to fake but upstream enough that you do not need months of pipeline data to learn from it.
Better still: track positive reply rate — replies that are interest, not "unsubscribe me" or "wrong person." A 12% reply rate that is 80% angry prospects is worse than a 6% reply rate that is 70% qualified interest. Tag replies as you triage them and report on the qualified slice.
| Metric | Reliable in 2026? | Why |
|---|---|---|
| Open rate | No | Apple MPP + corporate prefetchers inflate |
| Click rate | Partially | Link scanners click everything |
| Reply rate | Yes | Requires a human action |
| Positive reply rate | Yes (best) | Filters out unsubscribes and wrong-person replies |
| Meeting-booked rate | Yes | The metric that pays the bills |
| Revenue / pipeline | Yes (lagging) | Final ground truth, but slow to learn from |
What are the most common A/B testing mistakes?#
After auditing dozens of outbound programs, the same five mistakes show up everywhere.
1. Calling a winner too early. "Variant B has a 40% reply rate after 80 sends, variant A has 25%." Tempting to declare. Don't. With 80 sends, the 95% confidence interval on that 40% rate stretches from roughly 30% to 51%. The arms overlap. You have not learned anything yet. Wait for the predetermined sample size.
2. Testing too many variables at once. Variant A uses a question subject and a soft CTA. Variant B uses a stat-based subject and a hard CTA. If B wins, which change drove it? You cannot tell, and now the next test inherits the confusion.
3. Re-running the same test until it "works." If you run a test 20 times and pick the one that hit p<0.05, you have produced exactly one false positive — that is the definition of p<0.05. This is called p-hacking. The cure is to write down what you will test, when you will check the result, and what threshold counts as a win. Then stick to it.
4. Ignoring effect direction. A statistically significant result that says variant B replies 0.4 points more than variant A is technically a winner but operationally a tie. Define your MDE — the smallest lift worth shipping — and discard results below it.
5. Not segmenting the analysis. An overall win can hide that variant A crushed at SMB and got destroyed at enterprise. Always slice results by your two most important segments (company size, persona) before rolling out.

Which tools handle A/B testing well?#
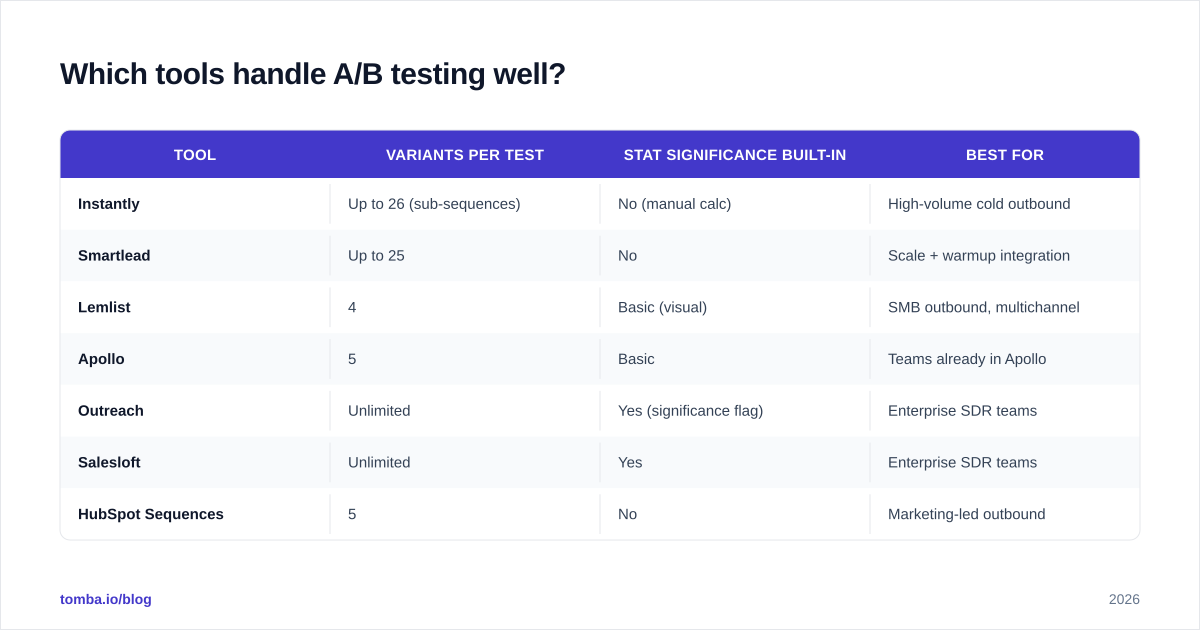
The shortlist below covers the sequencers that genuinely support clean A/B testing on cold outbound. "Genuinely" means contact-level randomization, simultaneous send, and reporting that exposes per-variant volume and confidence intervals.
| Tool | Variants per test | Stat significance built-in | Best for |
|---|---|---|---|
| Instantly | Up to 26 (sub-sequences) | No (manual calc) | High-volume cold outbound |
| Smartlead | Up to 25 | No | Scale + warmup integration |
| Lemlist | 4 | Basic (visual) | SMB outbound, multichannel |
| Apollo | 5 | Basic | Teams already in Apollo |
| Outreach | Unlimited | Yes (significance flag) | Enterprise SDR teams |
| Salesloft | Unlimited | Yes | Enterprise SDR teams |
| HubSpot Sequences | 5 | No | Marketing-led outbound |
The tools with built-in significance flags (Outreach and Salesloft) are convenient but still require you to set the sample size up front. None of them stop you from peeking — you have to enforce that yourself.
For everything else, drop the per-variant numbers into a simple two-proportion z-test calculator (or paste them into ChatGPT and ask for the z-score). It takes 30 seconds and saves you from rolling out copy that does nothing.
Pair the test mechanics with clean contact data — bad emails inflate bounces and depress the apparent reply rate of both variants asymmetrically depending on which contacts got which variant. Run lists through an email verifier before the test, not after.
How do you A/B test subject lines specifically?#
Subject lines are the most-tested element in email, and the most-misread. A few principles that actually hold up across tens of thousands of sends:
- Test categories, not phrasings. "Quick question about {{company}}" vs "Quick question about {{firstName}}" is a phrasing test — barely worth running. "Question-based subject" vs "Stat-based subject" vs "Curiosity-gap subject" is a category test — that teaches you something.
- Personalization tokens inflate open rates but rarely lift reply rates. Test whether they actually improve replies on your list. Often they do not.
- Length matters less than you think. Mobile preview cuts at ~35-40 characters; beyond that, length has weak effects. Don't agonize.
- Capitalization (Title Case vs sentence case) is one of the few "small" tests that consistently produces measurable differences. Sentence case usually wins for cold B2B because it looks less marketed.
For inspiration when you need fresh categories to test, a subject line generator helps you generate hypotheses faster than staring at a blank doc.
What does a good test calendar look like?#
Run one test at a time per sequence. Overlapping tests on the same audience contaminate each other.
A reasonable cadence for a team sending ~10,000 cold emails a month:
- Weeks 1-2: ICP / segment test (compare two distinct lists with identical copy).
- Weeks 3-4: Offer / value-prop test (two angles on the same ICP).
- Weeks 5-6: Opener test (problem-led vs trigger-led vs flattery-led).
- Weeks 7-8: CTA test (interest ask vs meeting ask vs resource offer).
- Weeks 9-10: Subject line category test.
- Weeks 11-12: Roll up learnings into a new control. Restart.
That cadence gives each test ~2,000 sends per variant on a single segment, which is enough to detect ~20% relative lifts at typical 5% reply baselines.
Closing: test what changes the business#
The teams that win at outbound do not run more tests than everyone else. They run better-designed tests on the variables that matter, with sample sizes that can actually detect the lift they care about. They write down their hypothesis, predetermine the sample size, and refuse to peek.
If you are setting up your first real A/B testing program, the highest-leverage first move is fixing the data feeding into both arms. Inconsistent emails, missed verifications, and stale contacts depress both variants by random amounts and make every test result mushier than it should be.
Tomba's email finder and verification stack give you the clean inputs you need to make your A/B tests trustworthy — accurate emails, verified deliverability, and consistent enrichment across both variants. Pair it with the testing discipline above and you will spend less time guessing which copy "feels better" and more time shipping copy that demonstrably moves replies. Try the free tier (25 searches/month) or compare Tomba pricing against your current data provider before your next test cycle.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author