How to A/B Test Reply Rates in Cold Email (2026 Guide)
A practical 2026 playbook for running A/B tests that actually move cold email reply rates — sample sizes, variables, statistical significance, and the traps that kill most experiments.

How to A/B Test Reply Rates in Cold Email (2026 Guide)
TL;DR
- Most cold email A/B tests are statistically meaningless — sample sizes are tiny, variables overlap, and inboxes vary too much for clean reads.
- To A/B test reply rates properly you need a single isolated variable, ~1,000+ sends per arm for a 2pp lift, and a sequential testing framework.
- Subject line tests are the most overrated. First-line personalization, offer framing, and CTA type produce the biggest reply lifts in 2026.
- Run tests inside one sending domain at a time, randomize at the prospect level, and ignore opens — track replies and positive replies separately.
- Tools like Instantly, Smartlead, and lemlist handle the mechanics; a clean list from Tomba is what makes the math work in the first place.
Why do most teams fail to A/B test reply rates?#
You've seen the screenshots on LinkedIn. "We changed one word in the subject line and replies went up 312%." Then nobody mentions the test ran on 80 sends per variant.
That's not a test. That's a coin flip with a hashtag.
When you ab test reply rates in cold email, you're trying to measure a small effect (a 1-3 percentage point lift) inside a noisy channel (inbox placement, time of day, prospect mood, day of week, deliverability drift). The signal is quiet. The noise is loud. Most "winning" variants you see in the wild are within the margin of error, and if you re-ran the same test next Tuesday you'd flip the result.
The teams that consistently improve reply rates treat A/B testing like a research process, not a Twitter post. Smaller experiments, fewer variables, harder evidence.

What counts as a valid A/B test in cold email?#
A valid test has five properties. Miss any one and you're guessing.
- One variable changes. Not "new subject line + new opener + new CTA." One thing.
- Random assignment at the prospect level. Not "send variant A on Monday, variant B on Tuesday." Day-of-week alone moves reply rates by 20-40%.
- Same sending infrastructure. Same domain, same mailbox pool, same warmup state. Different domains have different inbox placement, full stop.
- Pre-declared sample size. You decide how many sends before you peek. Stopping early when one variant looks better is the most common stats crime in this space.
- A meaningful primary metric. Reply rate, not open rate. Better yet: positive reply rate, since "unsubscribe" and "wrong person" replies inflate the headline number.
If your A/B tool doesn't let you control these — randomize at the prospect, hold infrastructure constant, lock sample sizes — you're not testing, you're vibing.
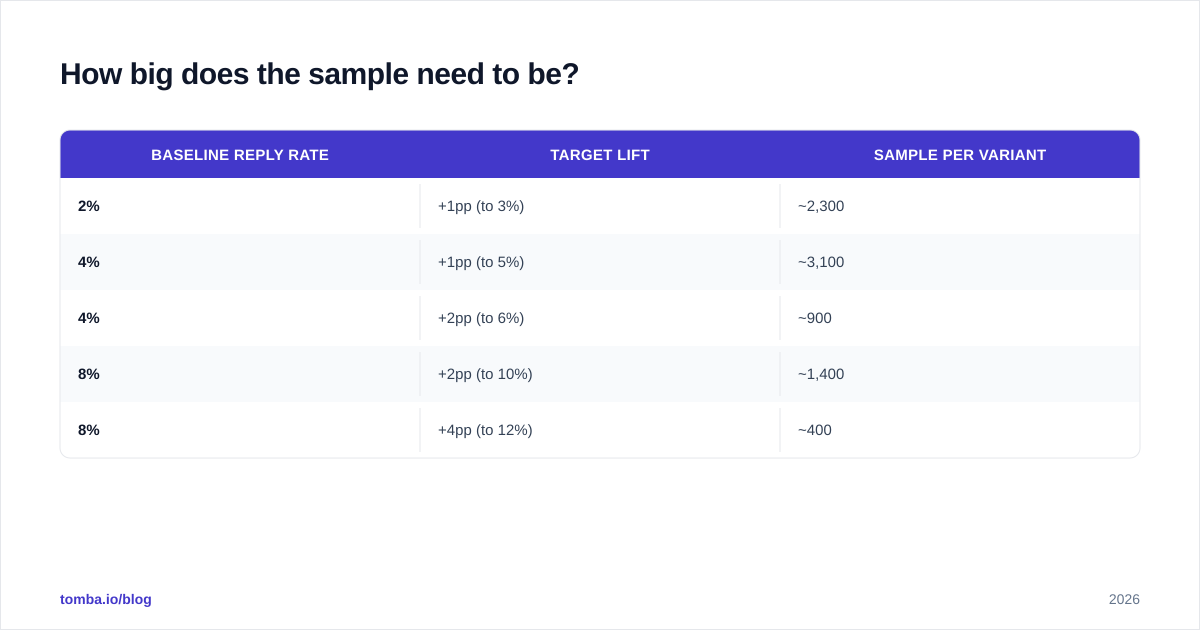
How big does the sample need to be?#
This is where most tests die before they start. The honest answer: bigger than you think.
For cold email, baseline reply rates usually sit between 2% and 8%. Detecting a relative lift of 20% (e.g. moving from 4% to 4.8%) at 80% power and 95% confidence requires roughly:
| Baseline reply rate | Target lift | Sample per variant |
|---|---|---|
| 2% | +1pp (to 3%) | ~2,300 |
| 4% | +1pp (to 5%) | ~3,100 |
| 4% | +2pp (to 6%) | ~900 |
| 8% | +2pp (to 10%) | ~1,400 |
| 8% | +4pp (to 12%) | ~400 |
So if you're running a campaign at 4% reply rate and you want to confidently detect a 1-point lift, you need around 6,200 sends in total — split evenly between variants. If your list is 400 prospects, you're not testing anything; you're shipping.
This is why building a clean, large enough list matters before you obsess over copy. A reliable email finder and a tight email verifier step give you the volume — and the deliverability — that makes the math work.

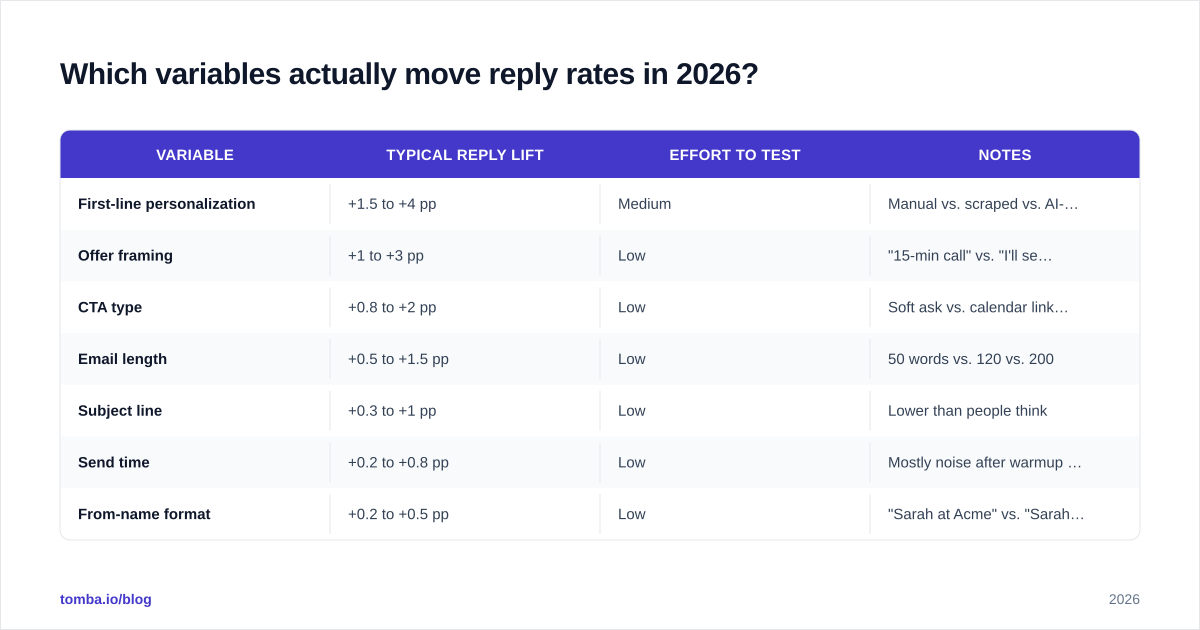
Which variables actually move reply rates in 2026?#
Not all variables are created equal. After watching thousands of B2B sequences, here's roughly how much each lever can move reply rate when tested in isolation. These are rough industry-observed ranges, not promises.
| Variable | Typical reply lift | Effort to test | Notes |
|---|---|---|---|
| First-line personalization | +1.5 to +4 pp | Medium | Manual vs. scraped vs. AI-generated |
| Offer framing | +1 to +3 pp | Low | "15-min call" vs. "I'll send you the doc" |
| CTA type | +0.8 to +2 pp | Low | Soft ask vs. calendar link vs. yes/no |
| Email length | +0.5 to +1.5 pp | Low | 50 words vs. 120 vs. 200 |
| Subject line | +0.3 to +1 pp | Low | Lower than people think |
| Send time | +0.2 to +0.8 pp | Low | Mostly noise after warmup is solid |
| From-name format | +0.2 to +0.5 pp | Low | "Sarah at Acme" vs. "Sarah Chen" |
Notice subject lines near the bottom. Subject lines drive opens, not replies. If your subject line is broken your open rate cratters and the rest of the funnel collapses — but among "decent" subject lines, swapping words rarely moves reply rate more than half a point. Treat it as a hygiene check, not your primary lever.
The real wins come from rethinking the offer — what you're asking the prospect to do and what they get out of it — and how convincingly the first line proves you know who they are.
How should you structure the test?#
The cleanest setup looks like this:
- Lock infrastructure. One sending domain, fully warmed, SPF/DKIM/DMARC aligned. Don't test across two domains — you'll measure deliverability, not copy.
- Build one list. Pull a single segment with a domain search and verify it. Mixed segments add variance.
- Randomize at the prospect. Most platforms (Instantly, Smartlead, lemlist) support this natively. If yours doesn't, randomize in a spreadsheet before import.
- Pre-declare sample size and stop date. Write it down. "We send 2,000 per arm, evaluate on day 14." No peeking.
- Track positive replies, not all replies. Tag manually or use the platform's reply classifier. Auto-responders and "remove me" replies don't count as wins.
- Run a sanity A/A test once a quarter. Send the same variant to two random halves of a list. If you get a "winner," your noise floor is too high and you need more volume per test.
The A/A test is the discipline most teams skip. It's also the one that proves whether your reads are real.
What's the difference between A/B, multivariate, and sequential testing?#
The terms get tossed around interchangeably. They aren't.
- A/B test: Two variants of one variable. Cleanest, slowest signal per cycle.
- Multivariate test: Multiple variables changed across multiple variants (e.g. 2 subjects × 3 openers = 6 cells). You need ~6× the sample size to read it confidently. Most teams don't have the list size for this.
- Sequential testing: You evaluate results as data arrives, but use a corrected significance threshold (e.g. mSPRT, Bayesian) that accounts for repeated peeking. Lets you stop early when a result is genuinely strong.
For most B2B outbound teams under 10,000 sends per week, stick with A/B and one variable at a time. Multivariate looks sophisticated but produces less learning per dollar of list spend.
If you're sending 50,000+ per week, sequential testing through a platform that supports it (or a custom Bayesian harness) gets you faster reads without the false positives.
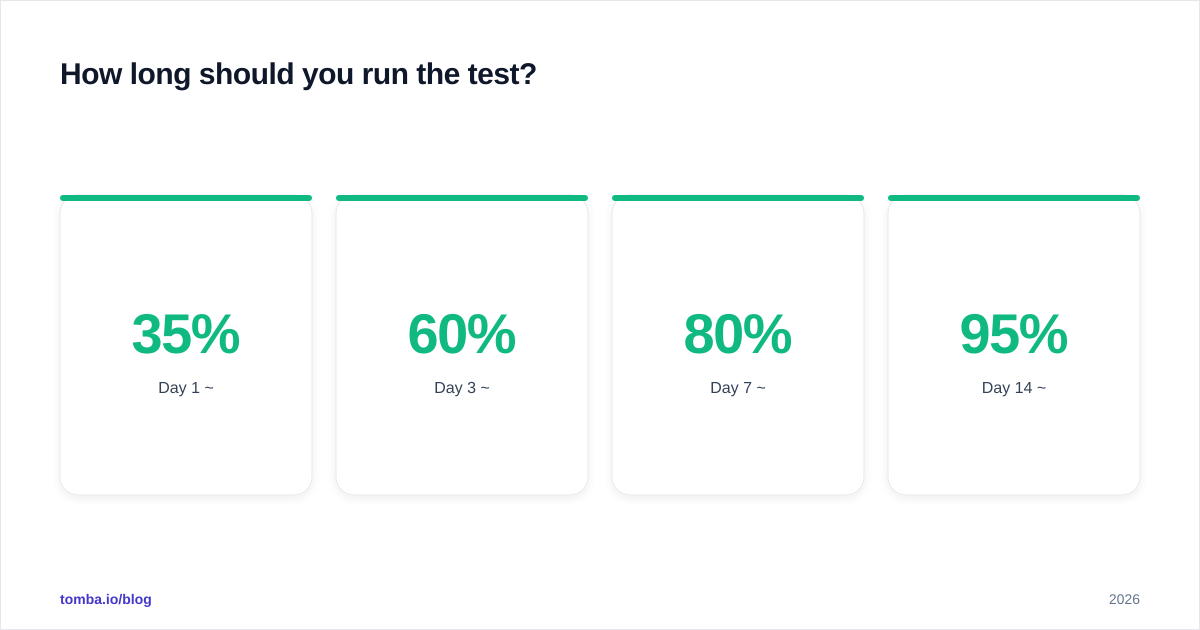
How long should you run the test?#
Long enough to clear the natural reply window, not so long that the world changes underneath you.
Reply curves for cold email look roughly like this:
| Days since send | Cumulative % of total replies |
|---|---|
| Day 1 | ~35% |
| Day 3 | ~60% |
| Day 7 | ~80% |
| Day 14 | ~95% |
| Day 21+ | ~100% |
Calling a test at day 3 means you're reading 60% of the signal — fine for directional, dangerous for decisions. Day 14 is the practical sweet spot. Day 21+ adds little.
If your sequence has follow-ups, decide upfront whether you're testing the first touch in isolation or the whole sequence together. Both are valid; mixing them is not.
What are the most common mistakes?#
In order of how often they kill tests in the wild:
- Tiny samples. "We tested it on 100 prospects" — you tested nothing.
- Multiple variables changed at once. Now you don't know what won, or whether anything did.
- Peeking and stopping early. Without sequential correction, this guarantees inflated false positive rates.
- Testing across days/weeks separately. Day-of-week and seasonality dominate the signal.
- Comparing across domains. Inbox placement varies; you're measuring deliverability.
- Ignoring positive reply quality. "Replies up 30%" — half of which are "unsubscribe."
- Reusing the same list. Prospects who saw variant A in week 1 contaminate variant B in week 3.
- Optimizing opens instead of replies. Opens are mostly a deliverability proxy now (especially with iOS MPP). Replies are revenue.
- No A/A baseline. You never confirmed your noise floor.

What tools handle the mechanics?#
You need three layers in the stack: list, sender, and analyzer.
| Layer | What it does | Common picks |
|---|---|---|
| List + verification | Source emails, verify before send | Tomba, Apollo, Clay |
| Sending platform | Randomize, send, track replies | Instantly, Smartlead, lemlist, Salesloft |
| Analysis | Sample size, significance, reply quality | Built-in (Smartlead/Instantly), custom dashboard, or a G2 cold email leaderboard check before purchase |
A clean prospect list isn't an A/B testing tool, but it's the upstream variable that makes everything else meaningful. Bad data inflates variance and buries small effects. Strong data enrichment and a bulk email finder workflow keep noise out of the test.
For the sending side, HubSpot's email benchmarks and Mailchimp's industry data give you a sanity check on whether your baseline reply rate even leaves room for the effect you're hunting. Testing inside an already-broken funnel is wasted volume.

How do you read results without fooling yourself?#
Three questions, in order:
- Is the lift statistically significant at your pre-declared threshold? Use a two-proportion z-test or a Bayesian posterior, not your eyeballs.
- Is the effect size practically meaningful? A 0.2pp lift on 4% baseline is real, statistically, and useless operationally if it took 10,000 sends to find.
- Does it replicate? Re-run the winner on a fresh segment. About 30-40% of "significant" wins fail to replicate, often because of segment drift or seasonality.
If a result passes all three, ship it. If it passes one or two, keep testing.
How do you build an A/B testing roadmap?#
Don't test randomly. Sequence experiments from highest-leverage to lowest.
A reasonable cold email A/B roadmap looks like:
- Baseline audit — measure current reply rate by segment, by domain, by sequence step. Find the weakest link.
- Offer test — biggest expected lift. Test two genuinely different value propositions, not two phrasings of the same one.
- First-line personalization test — manual vs. automated vs. AI-rewritten openers.
- CTA test — interest check vs. direct meeting ask vs. soft resource share.
- Length test — short vs. medium vs. long.
- Subject line test — only after the body is winning.
- Send time test — last, because effect sizes are tiny and warmup state confounds it.
Each test should take 2-3 weeks of sending. A serious team runs 12-15 high-quality tests per year, not 50 sloppy ones.
Final take#
A/B testing reply rates is less about clever copy and more about clean process. Lock infrastructure, isolate one variable, send enough volume, wait the full reply window, and pre-commit to a stopping rule. Do that with a verified prospect list and you'll learn something every quarter that compounds.
Most teams won't. Which is exactly why the ones that do pull ahead.
If you're rebuilding the foundation under your testing program, start with the list. Try the Tomba Email Finder on a free tier (25 searches/month) and run a verified segment through your next experiment — see what your real reply rate looks like once the bad addresses stop muddying the numbers. Pricing scales from $49/mo Starter to $249/mo Pro at Tomba pricing when you outgrow the free tier.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author