Account Based Targeting at Scale: The 2026 Playbook
Most ABM dies at 50 accounts. Here is how to run account based targeting at scale in 2026 without turning precision into spray-and-pray.

TL;DR
- Account based targeting at scale means running ABM precision across hundreds or thousands of accounts — not the hand-crafted 20-account model most teams start with.
- The bottleneck is never strategy. It's data coverage, contact-level accuracy, and signal routing. Fix those three and scale follows.
- Tier your accounts (1:1, 1:few, 1:many), then automate everything below Tier 1 with enrichment and intent signals.
- A clean account-to-contact data layer is the difference between scaling ABM and scaling waste.
- You can build the full motion on a sub-$100/month stack if you pick tooling that charges for accuracy, not seats.
What is account based targeting at scale?#
Account based targeting at scale is the practice of applying ABM discipline — pick the right accounts, reach the right buying committee, time the outreach to a real trigger — across a target list large enough that you cannot manage it by hand.
Here's the analogy. Classic ABM is a sniper: one rep, twenty named accounts, custom everything. Scaled ABM is a guided-missile battery: still precise, still target-locked, but firing at hundreds of accounts at once because the targeting and guidance are automated. The miss you want to avoid is turning the battery back into a shotgun the moment volume goes up.
That's the whole tension. The minute you go from 20 accounts to 2,000, the manual research that made ABM work collapses, and most teams quietly revert to spray-and-pray with an "ABM" label on it. Scaling the strategy is easy. Scaling the precision is the hard part, and it's almost entirely a data and tooling problem.

Why does ABM break when you try to scale it?#
Three things break, in this order:
- Account coverage thins out. Your ICP filter returns 1,800 accounts but your data vendor only has firmographics on 1,100 of them. You're already blind on 40% of the market.
- Contact-level data rots. Even where you have accounts, the buying committee — the 6 to 10 people who actually decide — is incomplete or stale. B2B contact data decays at roughly 30% per year, so a list built last quarter is already leaking.
- Signal routing has no home. A Tier-1 account hits your pricing page and nobody knows, because at scale the manual "watch these 20 logos" approach is impossible.
None of these are strategy failures. They're plumbing failures. According to Gartner research on B2B buying, a typical purchase now involves a buying group of six to ten stakeholders, each arriving with four or five independently gathered pieces of information. If your targeting only reaches one or two of them, you are not running ABM — you're running expensive lead-gen.
How do you tier accounts for scale?#
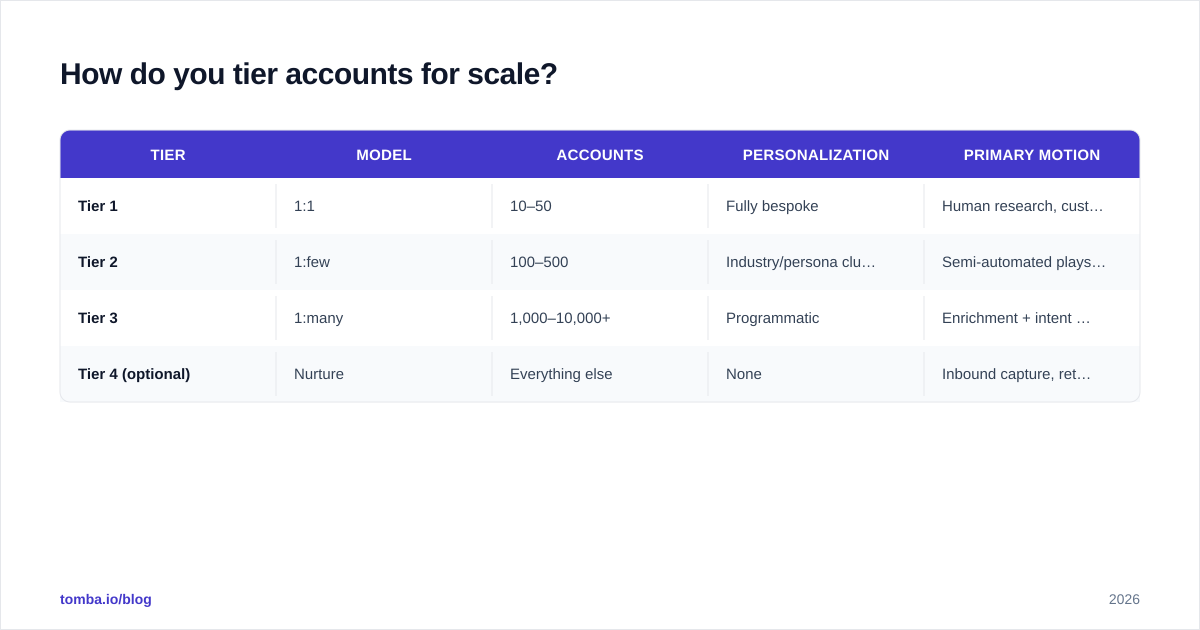
You don't treat all accounts equally — that's the entire point. The standard model splits your total addressable list into three tiers, each with a different cost-to-serve.
| Tier | Model | Accounts | Personalization | Primary motion |
|---|---|---|---|---|
| Tier 1 | 1:1 | 10–50 | Fully bespoke | Human research, custom assets, exec sponsorship |
| Tier 2 | 1:few | 100–500 | Industry/persona clusters | Semi-automated plays, light personalization |
| Tier 3 | 1:many | 1,000–10,000+ | Programmatic | Enrichment + intent + automated sequences |
| Tier 4 (optional) | Nurture | Everything else | None | Inbound capture, retargeting only |
The mistake is running every tier like Tier 1, then burning out after 30 accounts. The fix is the opposite: design Tier 3 first, because that's where scale lives, then layer human effort up the pyramid where the deal size justifies it.
For Tier 3 to work at all, the data layer has to be automated end to end. That's the section everyone skips and then wonders why their "scaled ABM" has a 0.4% reply rate.
What does the data layer for scaled ABM look like?#
Conclusion first: you need three joined data sets, refreshed continuously, or scale amplifies your errors instead of your results.
1. The account layer. Firmographics — industry, size, tech stack, revenue band — so your ICP filter returns a complete list, not a partial one. This is where a real B2B database earns its keep, because coverage gaps here cascade into everything downstream.
2. The contact layer. For every in-scope account, you need the buying committee mapped and reachable. This is the layer that rots fastest and where most "ABM at scale" programs silently fail. You can map the org chart perfectly, but if you can't find email addresses for those people, the map is decoration. A domain search that returns every known address at a company — with role and seniority — turns one account into a fully addressable buying group in seconds.
3. The signal layer. Intent data, website visits, job changes, funding events, tech adoption. Signals tell you which of your thousands of targeted accounts deserve attention this week.
The trick to scale is joining these so that a signal automatically pulls the right contacts and routes them into the right play. When a Tier-3 account lights up on intent, the system should enrich the buying committee, verify the emails, and drop them into a sequence without a human touching it.
Why verification is non-negotiable at volume#
At 20 accounts a bounced email is an annoyance. At 5,000 contacts a 12% bounce rate torches your sender reputation and your whole domain stops landing in inboxes. Scale punishes dirty data geometrically. Running every contact through an email verifier before it enters a sequence is the cheapest insurance in the entire motion — protect deliverability or the volume you fought to build works against you.
How do you keep targeting precise as volume grows?#
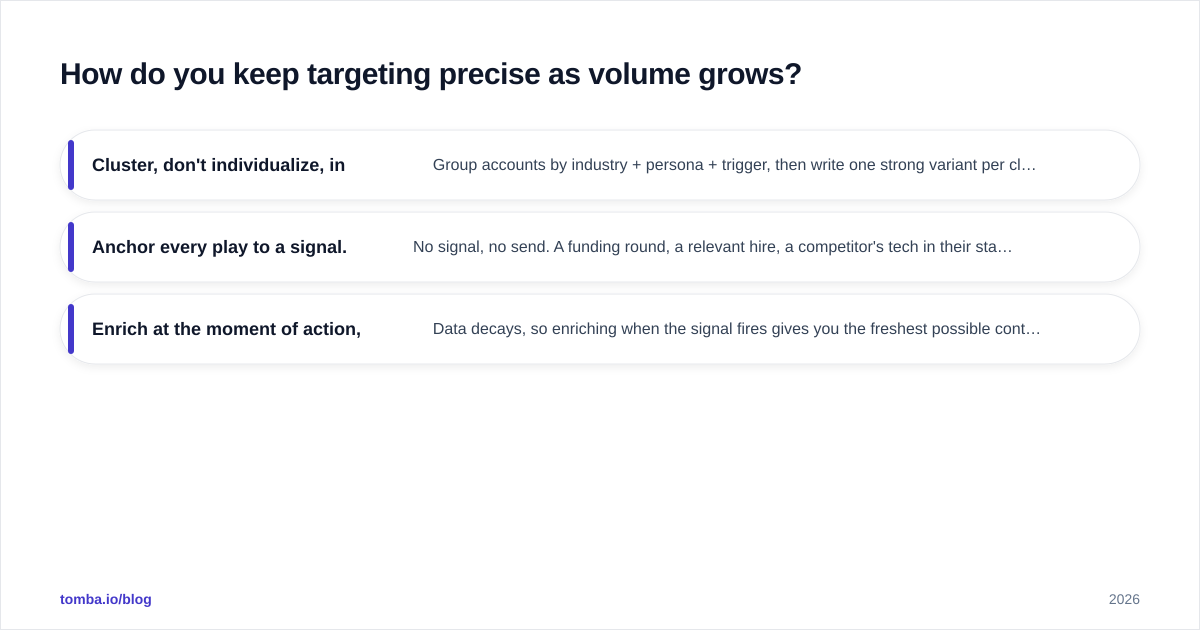
Precision at scale comes from segmentation discipline, not from manual review. Three practices keep the missiles guided:
- Cluster, don't individualize, in Tier 2/3. Group accounts by industry + persona + trigger, then write one strong variant per cluster. Fifteen clusters covering 1,500 accounts beats 1,500 limp "personalized" emails.
- Anchor every play to a signal. No signal, no send. A funding round, a relevant hire, a competitor's tech in their stack — the trigger is the relevance, which is what lets you skip per-contact research.
- Enrich at the moment of action, not in a batch. Data decays, so enriching when the signal fires gives you the freshest possible contact info. A batch enriched three months ago is already 8–10% wrong.
This is also where data enrichment and bulk lead generation stop being nice-to-haves. Scaled ABM is, mechanically, a continuous enrich-verify-route loop. The teams that win treat that loop as core infrastructure, the same way they'd treat their CRM.

Which tools do you actually need?#
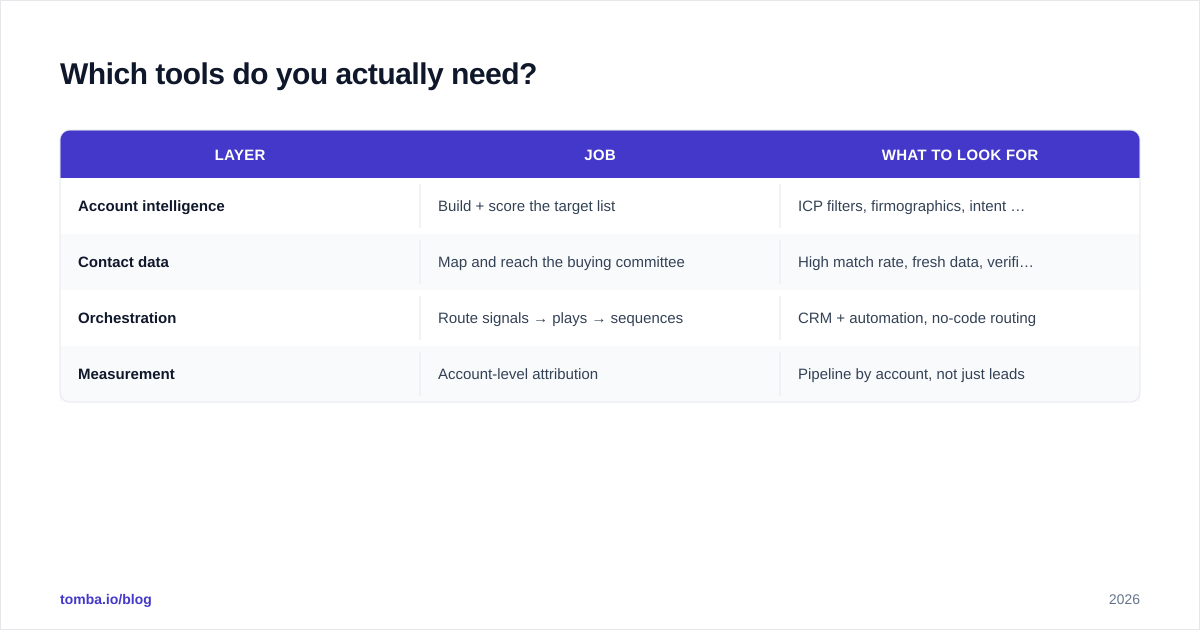
You need fewer than the vendor decks suggest. The functional stack for account based targeting at scale is four boxes:
| Layer | Job | What to look for |
|---|---|---|
| Account intelligence | Build + score the target list | ICP filters, firmographics, intent signals |
| Contact data | Map and reach the buying committee | High match rate, fresh data, verification built in |
| Orchestration | Route signals → plays → sequences | CRM + automation, no-code routing |
| Measurement | Account-level attribution | Pipeline by account, not just leads |
Plenty of all-in-one platforms bundle these — and charge accordingly, often $30k+/year with per-seat pricing that punishes you for adding reps. The unbundled approach is usually cheaper and more accurate: a dedicated contact-data tool that charges for results, plugged into the CRM and automation you already run.
For example, Tomba sits in the contact-data box. Its Tomba pricing runs Free (25 searches/mo), Starter at $49/mo, Growth at $99/mo, and Pro at $249/mo — credit-based, not seat-based, so a 3-person team and a 30-person team pay for the data they pull, not the headcount. You connect it to your CRM through native integrations or the Tomba API and the enrich-verify-route loop runs without manual exports. Compare that to the seat-tax model and the math at scale isn't close.
A quick reality check on the build-vs-buy question — independent reviews on G2 consistently show that match rate and data freshness, not feature count, separate the tools that survive contact with a real ABM program. Buy for accuracy; the bells and whistles age out.
How do you measure account based targeting at scale?#
Stop counting leads. At scale, lead counts actively mislead you — a 10,000-contact program will always generate impressive lead volume while the accounts you care about go cold.
Measure these instead:
- Account coverage: % of Tier-1/2 accounts with an active, multi-threaded play. Multi-threading matters; single-threaded deals in a 6–10 person committee stall.
- Engagement depth per account: how many committee members are engaged, not how many clicks total.
- Pipeline velocity by tier: are Tier-1 accounts actually moving faster than Tier-3? If not, your human effort is misallocated.
- Data health: bounce rate, enrichment match rate, % of accounts with a complete buying committee. These leading indicators predict pipeline a quarter out.
The frameworks from HubSpot's ABM guidance are a solid baseline here, but the principle is simple: if your dashboard's top metric is "leads," you've already reverted to the spray model.
What does a scaled play look like end to end?#
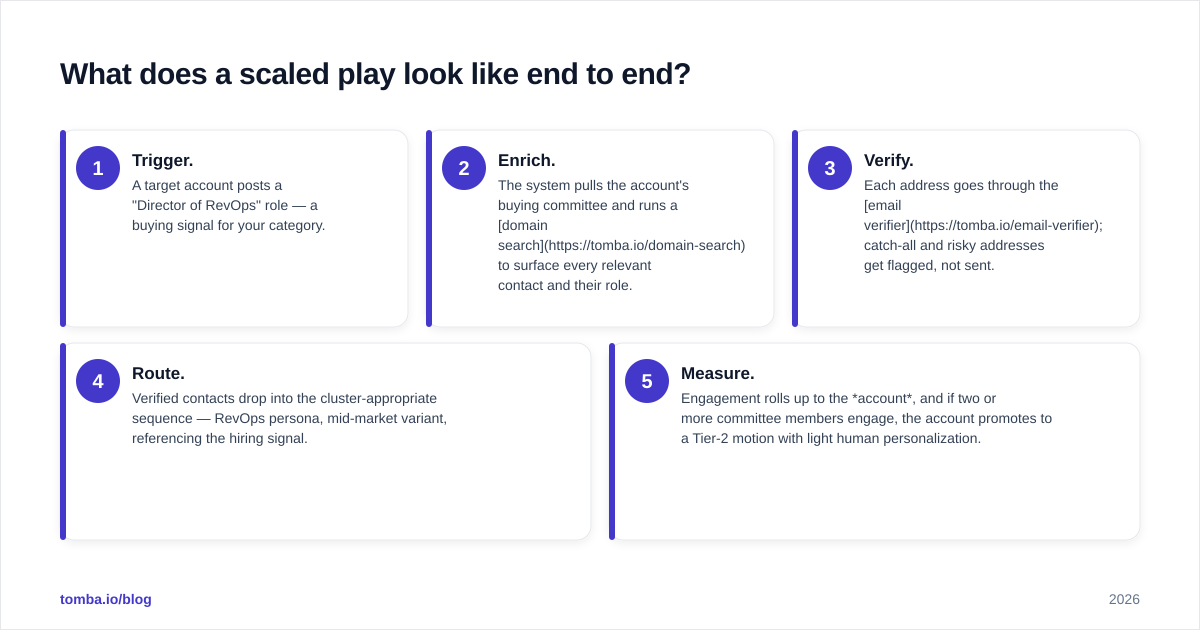
Walk one Tier-3 account through the loop:
- Trigger. A target account posts a "Director of RevOps" role — a buying signal for your category.
- Enrich. The system pulls the account's buying committee and runs a domain search to surface every relevant contact and their role.
- Verify. Each address goes through the email verifier; catch-all and risky addresses get flagged, not sent.
- Route. Verified contacts drop into the cluster-appropriate sequence — RevOps persona, mid-market variant, referencing the hiring signal.
- Measure. Engagement rolls up to the account, and if two or more committee members engage, the account promotes to a Tier-2 motion with light human personalization.
No human touched steps 1–4. That's the whole game: humans design the system and work Tier 1, the system handles the volume with the same precision a rep would — because the data underneath it is complete and fresh.
Common mistakes to avoid#
- Scaling before the data layer is clean. Volume on top of bad data is just faster failure. Fix coverage and verification first.
- Treating ABM and demand gen as enemies. At scale they merge. Your demand-gen captures intent; your ABM routes it to named accounts. Same plumbing.
- Over-personalizing Tier 3. Cluster-level relevance plus a real signal beats fake first-name-token "personalization" every time.
- Ignoring deliverability. The fastest way to kill a scaled program is a blacklisted domain. Verify everything, warm your domains, and watch bounce rates like a hawk.
- Buying seats instead of accuracy. Per-seat all-in-one suites make scale expensive on purpose. Unbundle the contact-data layer and pay for results.
Closing: build the data layer first#
Account based targeting at scale is not a strategy problem — it's a plumbing problem wearing a strategy costume. Get the account layer complete, the contact layer fresh and verified, and the signal layer wired to your plays, and scale stops being scary. Skip any of those and volume just amplifies the leak.
The cheapest, highest-leverage place to start is the contact-data layer, because nothing else works without it. The Tomba Email Finder turns a domain or a name into a verified, role-tagged email in seconds, plugs into your CRM, and bills on usage instead of seats — so you can map and reach buying committees across thousands of accounts without the enterprise-suite tax. Start on the free tier, wire it into your enrichment loop, and let the precision scale with you.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author