AI Customer Insights in 2026: Tools, Framework, and ROI
AI customer insights turn scattered CRM, product, and conversation data into next-best actions. Here is the 2026 framework, tooling, and pitfalls.

TL;DR
- AI customer insights are model-generated conclusions about who your buyers are, what they want, and what they will do next — built from CRM, product, support, and conversation data instead of gut feel.
- The value is not the dashboard. It is the next-best action: which account to call, which churn risk to flag, which message to send.
- You need three things before any model helps: clean contact data, unified event streams, and a tight feedback loop that proves whether the prediction was right.
- Most teams fail at the data layer, not the AI layer. Garbage contacts and duplicate accounts poison every downstream prediction.
- Start narrow — one use case, one measurable outcome — then expand. A churn-risk score that nobody acts on is worse than no score at all.
What are AI customer insights?#
AI customer insights are predictions and patterns a machine-learning system extracts from your customer data and hands back as something a human can act on. Think of it like a seasoned sales manager who has read every email, watched every demo, and remembers every renewal — except it never sleeps and never forgets.
In practice, "insights" covers a spectrum. On one end you have descriptive analytics: what happened (this account's usage dropped 40% last month). In the middle, predictive: what will happen (this account has a 70% chance of churning). On the far end, prescriptive: what to do about it (offer a success call this week and discount the annual plan).
The 2026 shift is that prescriptive output is finally usable. Large language models now read unstructured data — call transcripts, support tickets, email threads — and fuse it with structured CRM fields. That fusion is what makes the difference between a chart nobody opens and a Slack alert a rep actually clicks.
If you want the textbook definition, AI customer insight sits at the intersection of revenue operations and data science: it is RevOps deciding which questions matter, and ML answering them at scale.
Why do AI customer insights matter in 2026?#
Because the volume of buyer signal has outgrown human attention. A mid-market B2B team touches thousands of accounts across email, LinkedIn, product telemetry, billing, and support. No human reads all of it. AI does, and it surfaces the 2% that needs a decision today.
Three forces make this urgent now:
- Buyers self-educate before they talk to you. Most of the buying journey happens before a rep is involved, so the signals that predict intent are digital — content views, repeat visits, feature usage — not call notes.
- Cost pressure killed the "spray and pray" motion. Teams can no longer afford to email 10,000 unqualified contacts. Insights let you prioritize the few hundred that convert.
- The tooling matured. What required a data-science team in 2022 ships as a feature in your CRM in 2026.

The payoff is concrete. Teams that operationalize insights report higher win rates because reps spend time on accounts that are actually in-market, and lower churn because at-risk customers get flagged while there is still time to intervene. The keyword is operationalize — an insight that never reaches the person who can act on it generates exactly zero dollars.
How does an AI customer insights pipeline work?#
The pipeline has four stages, and each one fails differently. Here is the flow from raw data to a closed-loop action.
Stage 1 — Ingest and unify. Pull data from every system that touches the customer: CRM, product analytics, billing, support, marketing automation, and enrichment sources. The hard part is identity resolution — making sure "Acme Corp," "Acme Corporation," and "acme.com" are the same account. This is where bad contact data sabotages everything downstream. If your records are full of dead emails and duplicate companies, the model learns from noise.
Stage 2 — Enrich. Raw CRM rows are thin. You enrich them with firmographics (company size, industry, funding), technographics (what stack they run), and verified contact details. Clean enrichment is the difference between "this lead is at a 50-person SaaS company that just raised a Series B" and "this lead works at, uh, somewhere." Tools like data enrichment APIs fill those gaps before the model ever sees the row.
Stage 3 — Model and score. Now the ML runs: propensity-to-buy scores, churn-risk flags, lookalike account matches, sentiment from conversation data, and next-best-action recommendations. Modern stacks combine classic gradient-boosted models for scoring with LLMs for reading text.
Stage 4 — Activate and learn. The score routes to a human or an automation — a task in the rep's queue, a Slack alert, a triggered email. Then the critical step most teams skip: you record the outcome and feed it back. Did the flagged account actually churn? Did the "hot" lead convert? Without that loop, your model never improves and you can't prove ROI.
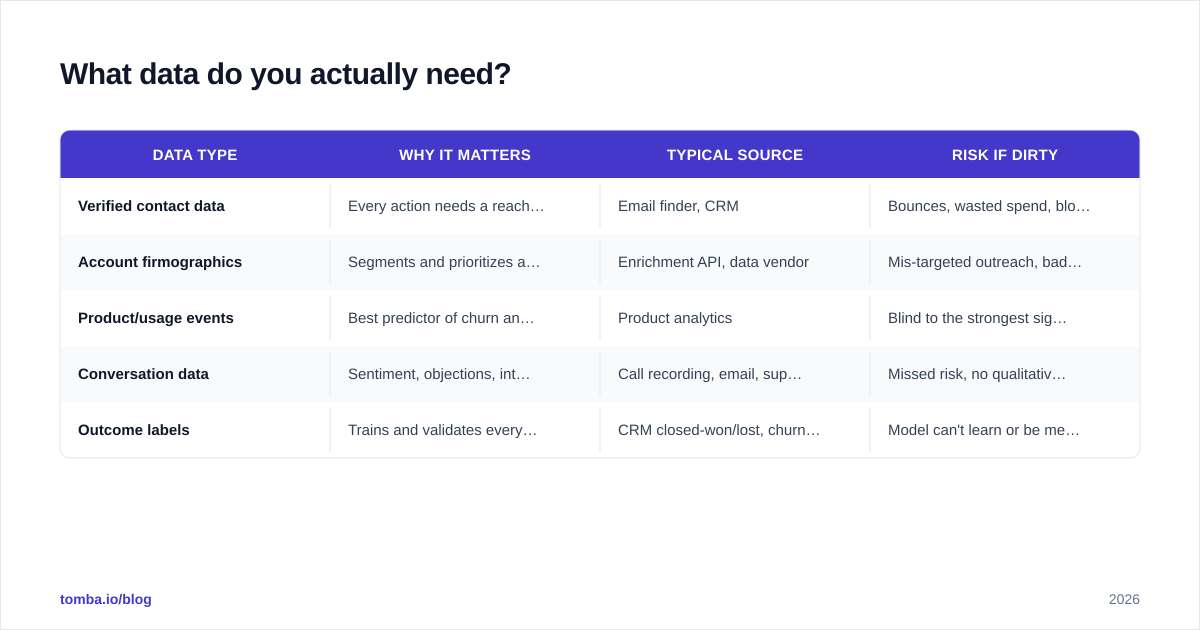
What data do you actually need?#
You need less data than vendors claim, but it has to be clean. Here is the priority order.
| Data type | Why it matters | Typical source | Risk if dirty |
|---|---|---|---|
| Verified contact data | Every action needs a reachable person | Email finder, CRM | Bounces, wasted spend, blocked sender reputation |
| Account firmographics | Segments and prioritizes accounts | Enrichment API, data vendor | Mis-targeted outreach, bad scoring |
| Product/usage events | Best predictor of churn and expansion | Product analytics | Blind to the strongest signal |
| Conversation data | Sentiment, objections, intent | Call recording, email, support | Missed risk, no qualitative context |
| Outcome labels | Trains and validates every model | CRM closed-won/lost, churn flag | Model can't learn or be measured |
Notice what sits at the top: verified contact data. You can have the smartest churn model in the world, but if the email it tells you to send bounces, the insight is worthless. This is why teams pair insight platforms with a reliable email verifier — the prediction layer is only as good as the deliverability layer underneath it.

A common mistake is hoarding data you'll never model. You do not need ten years of clickstream to start. You need the last 12 months of clean accounts, their outcomes, and the contact details to act on what you find.
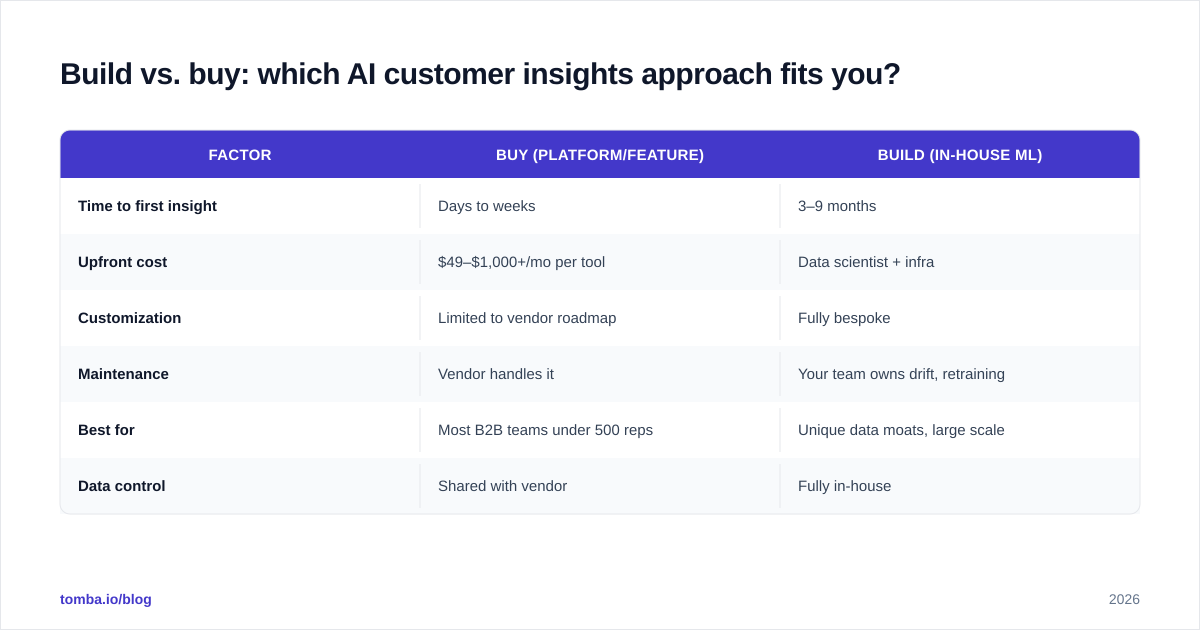
Build vs. buy: which AI customer insights approach fits you?#
Most teams should buy first and build later. Here is the honest comparison.
| Factor | Buy (platform/feature) | Build (in-house ML) |
|---|---|---|
| Time to first insight | Days to weeks | 3–9 months |
| Upfront cost | $49–$1,000+/mo per tool | Data scientist + infra |
| Customization | Limited to vendor roadmap | Fully bespoke |
| Maintenance | Vendor handles it | Your team owns drift, retraining |
| Best for | Most B2B teams under 500 reps | Unique data moats, large scale |
| Data control | Shared with vendor | Fully in-house |
The build path only pays off when your data or use case is genuinely unique and large enough to fund a team. For everyone else, a stack of focused tools beats a half-finished internal model. According to analyst coverage from firms like Gartner, the winning pattern in 2026 is composable: best-of-breed tools wired together, not one monolith.
A practical buy-side stack looks like this:
- Data foundation: a B2B database and enrichment layer to keep records complete and current.
- Conversation intelligence: a tool like Gong or its competitors to mine calls for sentiment and risk.
- Product analytics: event tracking to feed usage signals.
- CRM with native scoring: platforms such as HubSpot ship predictive lead scoring out of the box.
The glue between them — making sure a contact flagged in one system is reachable and verified in another — is where contact-data quality earns its keep.
How do you measure ROI on AI customer insights?#
You measure ROI by tying each insight to a decision and each decision to a dollar. If you can't draw that line, you bought a dashboard, not an insight engine.
Pick one of these as your first scorecard:
- Churn saved: accounts flagged at-risk that were retained after intervention, valued at their ARR.
- Pipeline lift: opportunities created from accounts the model prioritized vs. a control group you worked the old way.
- Rep efficiency: response rate and meetings booked per hundred contacts, before and after prioritization.
Run it as an A/B test. Give one team the AI-prioritized list, give another the status-quo list, and compare outcomes over a quarter. This is the only way to separate real signal from confirmation bias. A churn score that "feels accurate" is not evidence; a 9-point retention difference between cohorts is.
Beware the vanity metric trap. "Insights generated" and "models deployed" measure activity, not value. The number that matters is the change in a revenue outcome attributable to acting on the insight.

What are the biggest pitfalls?#
The failures are predictable, and almost all of them are human or data problems, not algorithm problems.
Dirty data in, dirty predictions out. This is the number-one killer. Duplicate accounts, stale emails, and missing firmographics quietly degrade every score. Fix the foundation before you blame the model. A periodic cleanse with a bulk email finder and verification pass keeps the inputs honest.
Insights with no owner. A churn flag that lands in a dashboard nobody checks is theater. Every insight needs a routing rule: who gets it, in which tool, with what SLA to act.
Over-trusting the black box. Reps stop thinking when the tool always tells them what to do — until it's confidently wrong. Keep humans in the loop, show them why the model scored something, and let them override with feedback that retrains it.
Privacy and compliance gaps. Customer data carries obligations. Make sure enrichment and storage respect consent and regional rules; review vendor data sourcing, like Tomba's published data sources, before you pipe anything into a model.
Boiling the ocean. Teams try to predict everything at once and ship nothing. Start with a single use case — say, churn risk for your top 200 accounts — prove it, then expand.
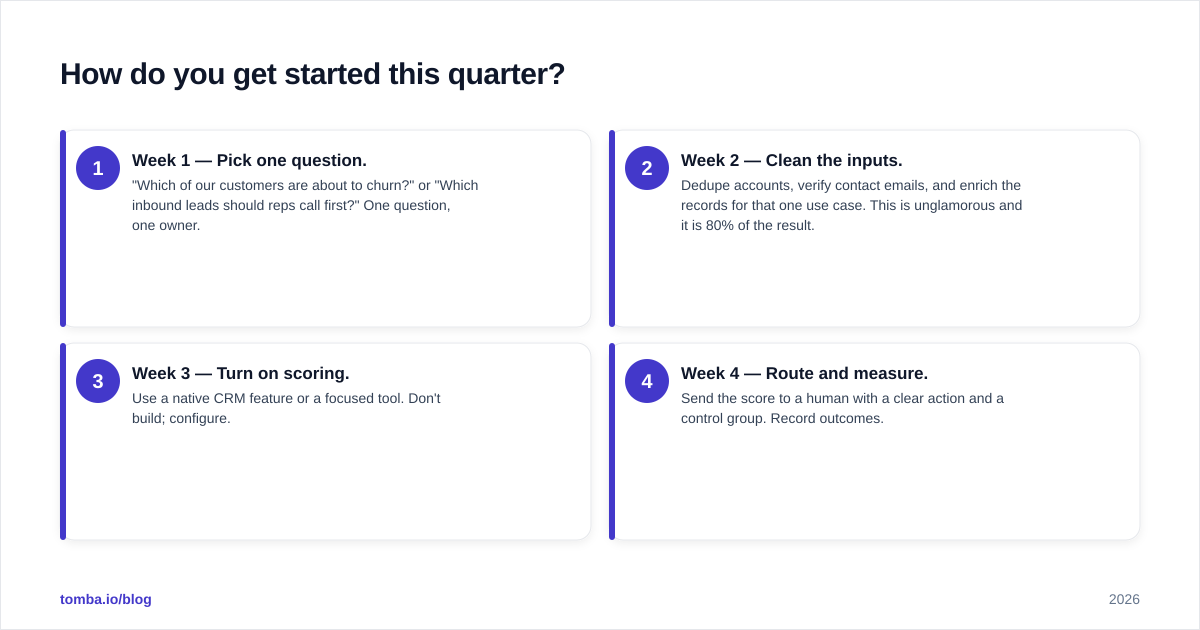
How do you get started this quarter?#
Start with the smallest loop that produces a decision. Here is a 30-day plan that doesn't require a data-science hire.
- Week 1 — Pick one question. "Which of our customers are about to churn?" or "Which inbound leads should reps call first?" One question, one owner.
- Week 2 — Clean the inputs. Dedupe accounts, verify contact emails, and enrich the records for that one use case. This is unglamorous and it is 80% of the result.
- Week 3 — Turn on scoring. Use a native CRM feature or a focused tool. Don't build; configure.
- Week 4 — Route and measure. Send the score to a human with a clear action and a control group. Record outcomes.
By day 30 you have a working loop and the first evidence of whether the insight moves a number. From there, every new use case is a repeat of the same pattern.
The thread running through all of it is contact-data quality. AI customer insights are predictions about people, and you can only act on a prediction if you can reach the person it points to. That is the layer most teams underinvest in and the one that quietly determines whether everything above it works.
Closing: get the data layer right first#
Before you shop for another AI insights platform, fix what it will run on. Predictions about accounts you can't contact are just expensive guesses. Tomba Email Finder gives your insight pipeline the clean, verified contact data it needs — find professional emails by domain, name, or company, then verify them so every next-best action actually reaches a real inbox. Start free with 25 searches a month, and scale on the Starter plan at $49/mo once the loop is paying off. Build the data foundation first; the insights are only as smart as the records beneath them.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author