B2B Personalization in 2026: Tactics, Tiers & Data Stack
B2B personalization fails when it's just a {{first_name}} token. Here's how to tier personalization by segment, source the data behind it, and scale 1:1 relevance without burning your team in 2026.

B2B personalization stopped meaning "Hi {{first_name}}" years ago. In 2026, buyers see hundreds of templated emails a week, and they pattern-match the fakes in under a second. Real personalization is about relevance — proving you understand a specific company's situation before you ask for their time. The hard part isn't the writing. It's the data and the process behind it.
This guide breaks down what B2B personalization actually requires today: the tiers worth investing in, the data stack that powers them, honest benchmarks, and how to scale 1:1 relevance without melting your reps.
TL;DR#
- Personalization is a data problem, not a copywriting problem. The best opener fails if the email lands in the wrong inbox or references stale information.
- Tier your effort by deal size. 1:1 manual research for enterprise, signal-based templates for mid-market, segment-based for SMB. Don't personalize everything equally.
- Relevance beats flattery. A trigger event ("you just hired 3 SDRs") outperforms a compliment ("love your blog") every time.
- Bad data kills personalization at the source. Start with verified contacts and enriched firmographics before you write a word.
- Tools like Tomba supply the verified emails and enrichment that make personalization land in the right inbox in the first place.
What is B2B personalization, really?#
B2B personalization is the practice of tailoring outreach, content, and offers to a specific account or buyer based on what you actually know about them — their role, company, industry, tech stack, recent activity, and pain points. Think of it like a good salesperson at a trade show: instead of handing the same flyer to everyone who walks by, they read your badge, notice your company, and open with something relevant to you.
Technically, it spans three layers:
- Account-level (firmographic): company size, industry, revenue, location, growth stage.
- Contact-level (role-based): job title, seniority, department, responsibilities.
- Behavioral / signal-level: funding rounds, new hires, tech adoption, website visits, content engagement.
The mistake most teams make is treating personalization as a writing step at the end. In reality, it starts with data collection — and if that data is wrong or missing, the cleverest copy in the world bounces or lands flat.
)
Why does most B2B personalization fail?#
Most "personalized" outreach fails for three predictable reasons, and none of them are about tone.
It's superficial. A merge tag with the prospect's first name and company isn't personalization — it's automation cosplaying as effort. Buyers know what a mail merge looks like.
It's based on stale or wrong data. If your CRM says someone is a "Marketing Manager" but they were promoted to VP eight months ago, your "personalized" line is now an insult. According to Gartner research on data decay, B2B contact data degrades at roughly 30% per year, which means a quarter of your database is wrong before you even start.
It doesn't reach the inbox. This is the silent killer. You can write the perfect 1:1 email, but if you're using a guessed or unverified address, it bounces — tanking your sender reputation and pushing future emails to spam. Personalization assumes deliverability, and deliverability assumes verified data.
The fix for all three starts upstream: get accurate, fresh contact and company data, then build your message on top of it.
What are the tiers of B2B personalization?#
Not every prospect deserves 20 minutes of research. The smartest teams tier their personalization effort to match deal value and volume. Here's a practical framework.
| Tier | Best for | Effort per contact | What you personalize | Scale method |
|---|---|---|---|---|
| 1:1 Deep | Enterprise / strategic accounts | 15–30 min | Specific pain, named stakeholders, recent initiatives | Manual research + AE |
| Signal-based | Mid-market | 3–5 min | Trigger events (funding, hires, tech changes) | Intent data + templates |
| Segment-based | SMB / high volume | <1 min | Industry, role, company size | Dynamic fields + segments |
| Basic merge | Newsletters, nurture | Seconds | Name, company | Automation only |
The goal is to push as much volume as possible into the lower tiers efficiently, while reserving your team's expensive manual time for accounts where a closed deal justifies it. A common ratio: spend 80% of your manual effort on the 20% of accounts that drive most of the revenue.
To execute the middle tiers well, you need enriched data at scale — firmographics, role data, and signals attached to verified contacts. That's where data enrichment and bulk lead generation workflows earn their keep: you append the attributes that feed your dynamic fields and segment logic without hand-researching each row.

How do you collect the data behind personalization?#
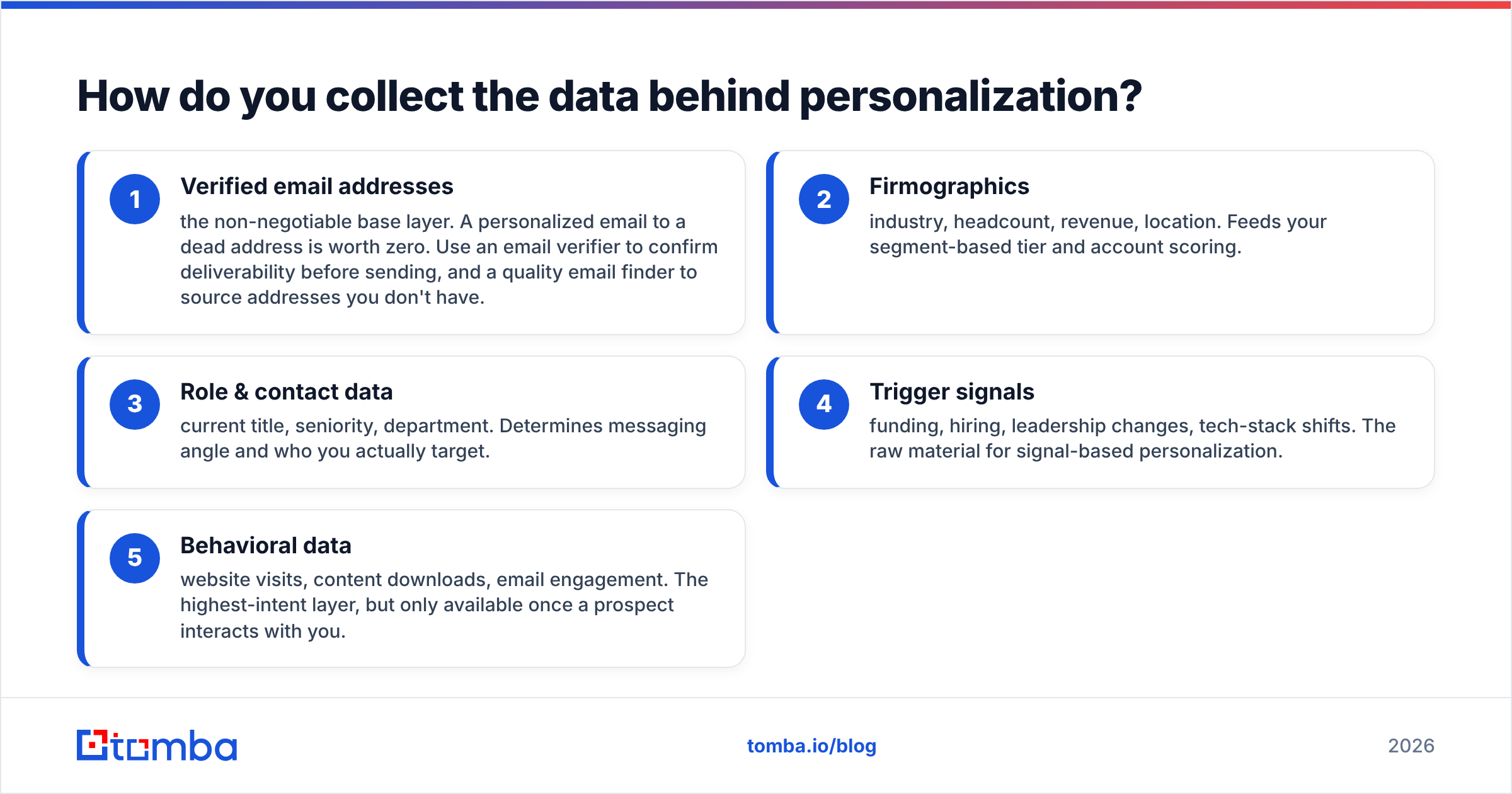
Every personalization tier runs on the same fuel: accurate data. Here's the stack, ordered by how foundational each layer is.
- Verified email addresses — the non-negotiable base layer. A personalized email to a dead address is worth zero. Use an email verifier to confirm deliverability before sending, and a quality email finder to source addresses you don't have.
- Firmographics — industry, headcount, revenue, location. Feeds your segment-based tier and account scoring.
- Role & contact data — current title, seniority, department. Determines messaging angle and who you actually target.
- Trigger signals — funding, hiring, leadership changes, tech-stack shifts. The raw material for signal-based personalization.
- Behavioral data — website visits, content downloads, email engagement. The highest-intent layer, but only available once a prospect interacts with you.
Each layer compounds. Verified contact + firmographics gets you a clean segment. Add a trigger signal and you've got a timely, relevant reason to reach out. Add behavioral data and you're responding to intent, not interrupting cold.
The practical bottleneck is usually layer 1. Teams jump to clever signals while sending to unverified addresses. Fix the foundation first — it's cheaper than rewriting your messaging.
)
Which personalization signals actually move the needle?#
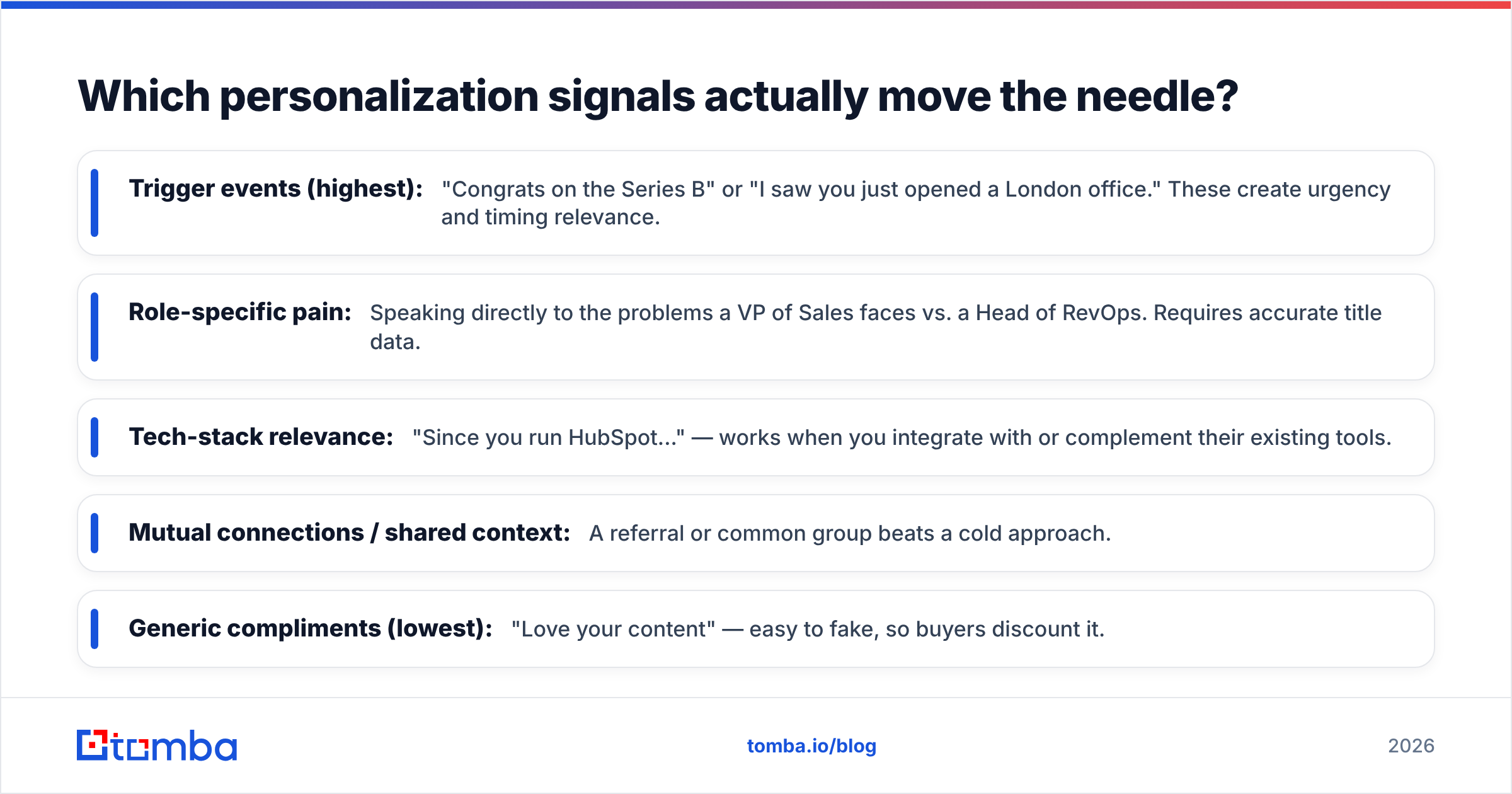
Not all signals are equal. Based on what consistently lifts reply rates in outbound, here's a rough hierarchy from highest to lowest impact:
- Trigger events (highest): "Congrats on the Series B" or "I saw you just opened a London office." These create urgency and timing relevance.
- Role-specific pain: Speaking directly to the problems a VP of Sales faces vs. a Head of RevOps. Requires accurate title data.
- Tech-stack relevance: "Since you run HubSpot..." — works when you integrate with or complement their existing tools.
- Mutual connections / shared context: A referral or common group beats a cold approach.
- Generic compliments (lowest): "Love your content" — easy to fake, so buyers discount it.
The pattern is clear: the more specific and timely a signal, the more it works. Generic flattery is the personalization equivalent of empty calories — it feels like effort but converts poorly. If you want to layer in phone-based follow-up for high-tier accounts, sourcing direct B2B phone numbers lets you multi-thread the same relevant message across channels.
How is AI changing B2B personalization in 2026?#
AI made personalization cheaper to produce — and that's a double-edged sword. Anyone can now generate a "personalized" opener in seconds, which means buyers' inboxes are flooded with AI-templated outreach that all sounds the same. The result: the bar for genuine relevance went up, not down.
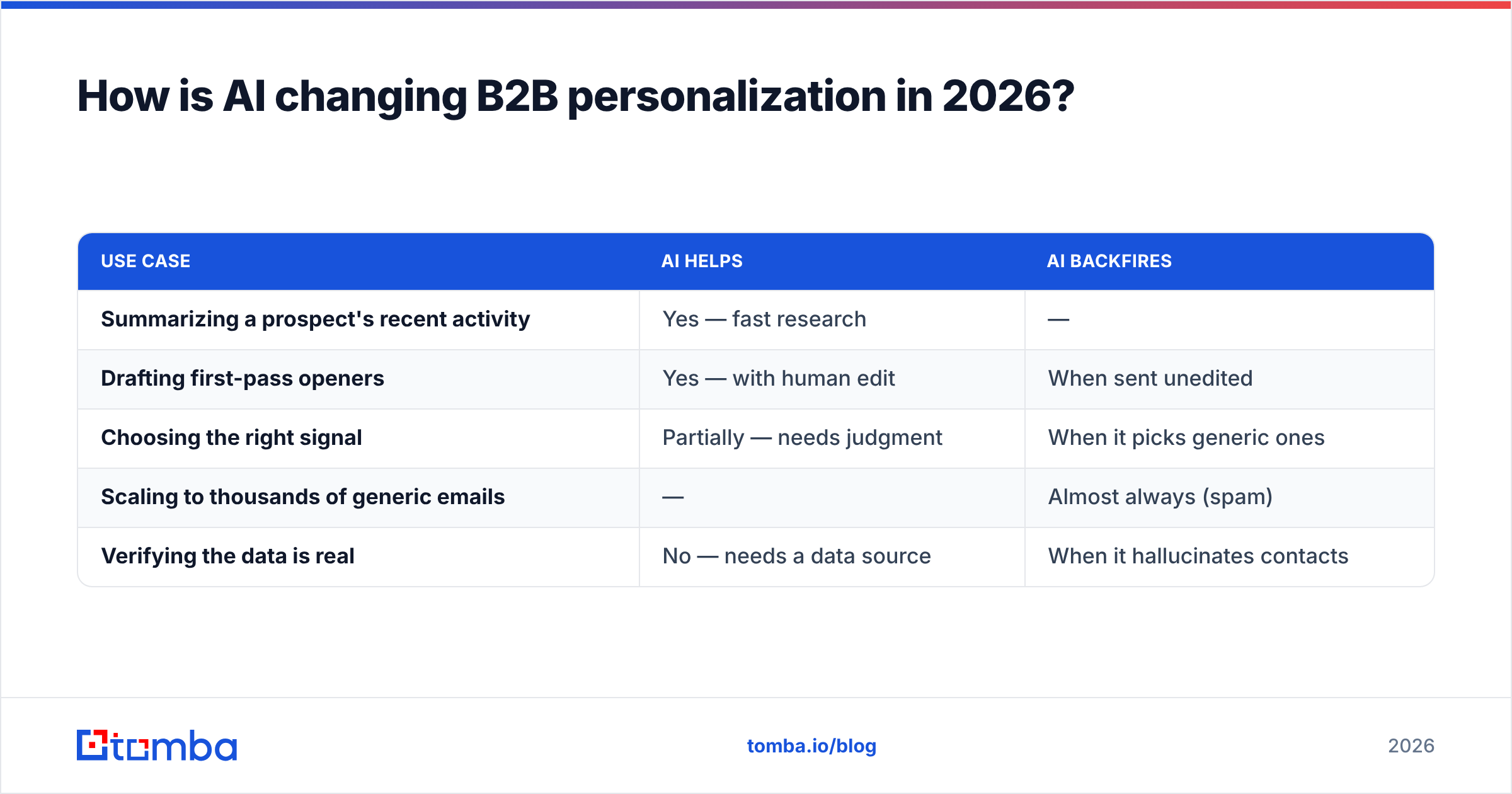
Here's where AI genuinely helps versus where it backfires.
| Use case | AI helps | AI backfires |
|---|---|---|
| Summarizing a prospect's recent activity | Yes — fast research | — |
| Drafting first-pass openers | Yes — with human edit | When sent unedited |
| Choosing the right signal | Partially — needs judgment | When it picks generic ones |
| Scaling to thousands of generic emails | — | Almost always (spam) |
| Verifying the data is real | No — needs a data source | When it hallucinates contacts |
The winning approach in 2026 is AI-assisted, human-directed: let AI compress research time, but keep a human deciding which signal matters and whether the email actually sounds like a person wrote it. And critically — AI cannot invent verified contact data. It will confidently hallucinate an email address that doesn't exist. Pair AI drafting with a real data source so you're personalizing to actual, reachable humans.
Vendors like HubSpot and review platforms like G2 both report that AI-generated outreach without verified targeting and human editing underperforms — the volume goes up, but reply rates fall.
How do you scale personalization without burning out your team?#
Scaling personalization is an operations problem. The answer isn't "personalize more" — it's "personalize smarter at each tier." Three principles:
1. Automate the data layer, humanize the message layer. Use enrichment and verification tools to assemble clean, signal-rich contact records automatically. Reserve human creativity for the parts that actually need it — the angle and the opener. Pull contacts straight into your workflow with a Chrome extension or push them through your existing integrations so reps never copy-paste.
2. Build snippet libraries by segment and signal. Instead of writing from scratch, maintain tested opener blocks keyed to common triggers (funding, hiring, role change). Reps assemble rather than author. This is how signal-based personalization stays fast without becoming generic.
3. Measure relevance, not volume. Track reply rate and positive-reply rate per tier, not just emails sent. If your signal-based tier replies at 8% and your basic-merge tier at 1%, that data tells you where to invest more research time.
The teams that win don't personalize everything — they personalize the right things and let verified data carry the rest. For account-level workflows, domain search lets you map every relevant contact at a target company in one step, so you can multi-thread a personalized play across the buying committee instead of pinging one inbox.
What does good B2B personalization look like in practice?#
Here's a concrete before-and-after, using the tier framework above.
Generic (basic merge):
Hi {{first_name}}, I wanted to reach out about how {{company}} could benefit from our sales platform. Do you have 15 minutes this week?
Signal-based:
Hi Maria — saw RevOps Inc. posted three SDR roles this month. Teams scaling outbound that fast usually hit the same wall: reps burning hours on bad contact data. Worth a quick comparison of how you're sourcing leads today?
The second works because it's built on a real signal (hiring), names a specific pain tied to that signal, and earns the ask. It took maybe four minutes — most of which was pulling the signal and verifying Maria's email, both of which can be automated.
That's the whole game: data does the heavy lifting, the human adds the judgment, and the message proves you paid attention.
The bottom line#
B2B personalization in 2026 is won upstream. The cleverest opener can't save a message sent to a stale or fake address, and the most expensive AI can't manufacture a relevant signal out of thin air. Start with verified, enriched data — then tier your human effort where it pays off.
If you want personalization that actually lands in the right inbox, start with the data layer. Tomba's Email Finder sources and verifies professional email addresses by name, company, or domain — and pairs with enrichment, domain search, and bulk workflows so your team personalizes to real, reachable buyers instead of guesses. The free tier gives you 25 searches a month to test it; paid plans start at $49/mo. Check Tomba pricing to match a plan to your volume, and build your next campaign on data you can trust.
Ready to find emails that actually work?
Join 150,000+ professionals who stopped guessing and started sending. Free credits on signup — no credit card required.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author