80legs Alternatives in 2026: 9 Better Web Scrapers Ranked
80legs feels stuck in 2014. Here are the 9 best 80legs alternatives in 2026 — ranked by accuracy, pricing, and scraping limits — plus where B2B data tools like Tomba fit in.

TL;DR
- 80legs is a budget distributed crawler that has barely evolved since 2014 — slow dashboards, unreliable concurrency, and no built-in proxy rotation make it a poor fit for modern scraping or B2B data needs.
- The strongest general-purpose 80legs alternatives in 2026 are Apify, Bright Data, ScrapingBee, Octoparse, and ParseHub — each one solves a specific failure mode of 80legs.
- If your actual goal is B2B contact data (emails, phones, company info) rather than raw HTML, a data API like Tomba is dramatically cheaper and faster than scraping the open web yourself.
- Expect to pay $30–$500/month depending on volume. The "cheap" path (running scrapers on your own infra) almost always costs more in engineering hours than a managed API.
- Pick by job-to-be-done: large-scale crawling (Apify, Bright Data), no-code extraction (Octoparse, ParseHub), API-first HTML (ScrapingBee, ScraperAPI), or skip scraping entirely and buy the data (Tomba, Clearbit).
Why are people looking for 80legs alternatives in 2026?#
80legs launched in 2009 with a clever idea: distribute crawling across volunteer machines and charge by URL crawled rather than by bandwidth. For a while, it was the cheapest way to crawl the web at scale.
Twelve years later, the product still looks and behaves like it did then. The dashboard is dated, concurrency caps are rigid, JavaScript rendering is unreliable on modern single-page apps, and there is no native proxy rotation — which means any site with even basic bot detection will block you within minutes. The pricing pages list plans starting at $29/month, but the practical ceiling is low enough that most users outgrow it during their first real project.
The market has moved on. Apify, Bright Data, ScrapingBee, and a dozen others now handle the parts 80legs never modernized: headless Chrome at scale, residential proxies, anti-bot bypass, scheduled runs, and proper APIs. And for users whose "scraping" is really just "I need verified email addresses," buying contact data from a B2B database is an order of magnitude faster than building a crawler at all.
This guide ranks nine real 80legs alternatives across three buckets — full scraping platforms, no-code extractors, and B2B data APIs — so you can pick by job, not by hype.
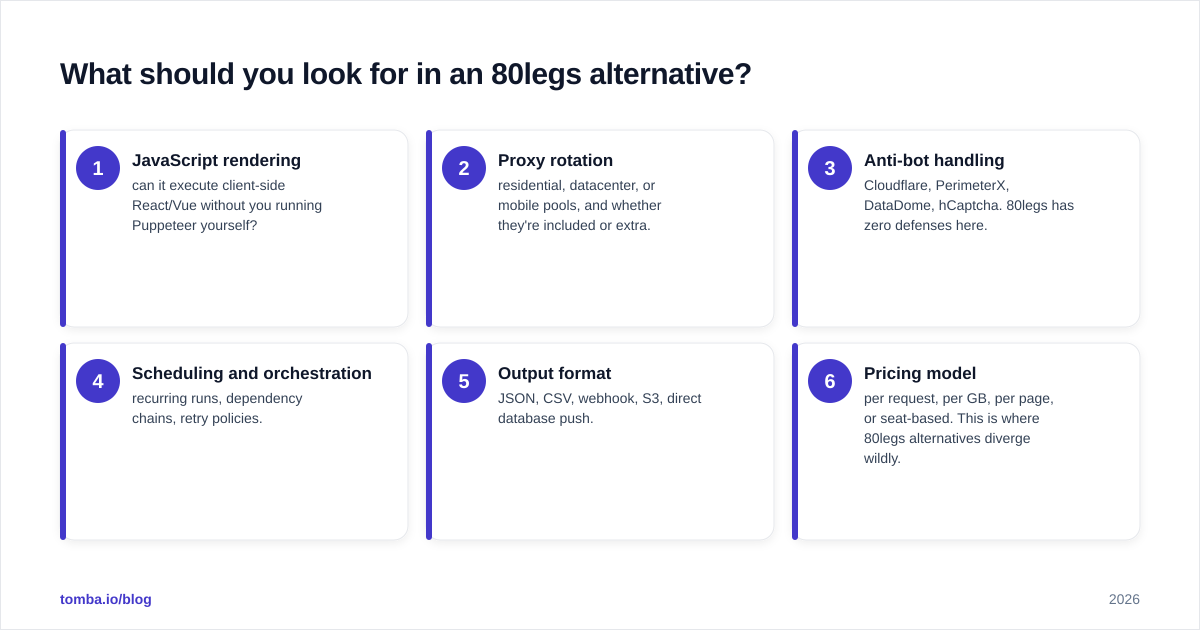
What should you look for in an 80legs alternative?#
Before the rankings, here are the six attributes that actually matter when you switch off 80legs:
- JavaScript rendering — can it execute client-side React/Vue without you running Puppeteer yourself?
- Proxy rotation — residential, datacenter, or mobile pools, and whether they're included or extra.
- Anti-bot handling — Cloudflare, PerimeterX, DataDome, hCaptcha. 80legs has zero defenses here.
- Scheduling and orchestration — recurring runs, dependency chains, retry policies.
- Output format — JSON, CSV, webhook, S3, direct database push.
- Pricing model — per request, per GB, per page, or seat-based. This is where 80legs alternatives diverge wildly.

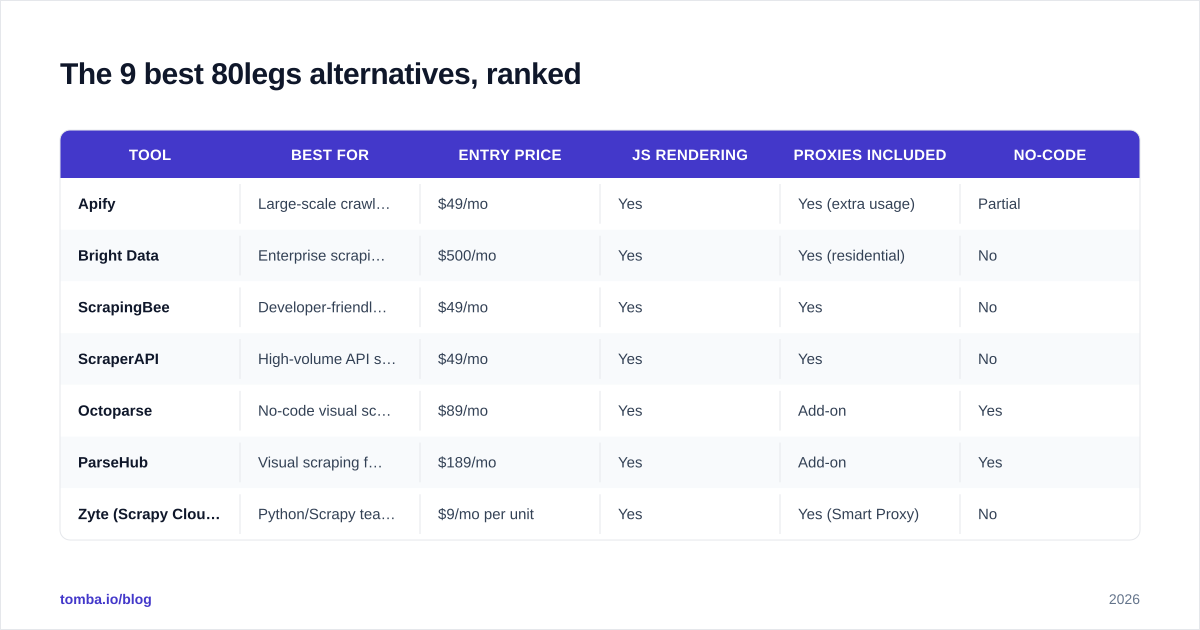
The 9 best 80legs alternatives, ranked#
Below is the head-to-head comparison. Pricing is the entry tier as of early 2026 — every vendor on this list also offers enterprise plans.
| Tool | Best for | Entry price | JS rendering | Proxies included | No-code |
|---|---|---|---|---|---|
| Apify | Large-scale crawling & actors | $49/mo | Yes | Yes (extra usage) | Partial |
| Bright Data | Enterprise scraping at any scale | $500/mo | Yes | Yes (residential) | No |
| ScrapingBee | Developer-friendly API | $49/mo | Yes | Yes | No |
| ScraperAPI | High-volume API scraping | $49/mo | Yes | Yes | No |
| Octoparse | No-code visual scraping | $89/mo | Yes | Add-on | Yes |
| ParseHub | Visual scraping for analysts | $189/mo | Yes | Add-on | Yes |
| Zyte (Scrapy Cloud) | Python/Scrapy teams | $9/mo per unit | Yes | Yes (Smart Proxy) | No |
| Tomba | B2B email & contact data | $49/mo | N/A (API) | N/A | Yes |
| Clearbit | Company enrichment | Custom | N/A | N/A | Yes |
1. Apify — best overall replacement#
Apify is the closest spiritual successor to 80legs' original mission: distributed crawlers, marketplace of pre-built scrapers ("Actors"), and pay-per-use pricing. The difference is twelve years of engineering polish. You get headless Chrome, proxy rotation, cron scheduling, a real REST API, and integrations with Zapier, Make, and Airbyte out of the box.
Entry plan is $49/month with $49 in platform credits. If you're a developer who wants to write a crawler and not babysit infrastructure, this is the default pick.
2. Bright Data — enterprise scraping at any scale#
Bright Data (formerly Luminati) is what large e-commerce, finance, and ad-tech teams use when they need to pull millions of pages a day. Their residential proxy network is the largest in the industry, and their Web Unlocker product handles Cloudflare and PerimeterX automatically.
The trade-off is price and complexity. Entry plans start at $500/month and the dashboard has a learning curve. Skip Bright Data if you're scraping a few thousand pages a week — it's overkill.
3. ScrapingBee — best API for developers#
If you just want a single HTTP endpoint that returns rendered HTML for any URL, ScrapingBee is the cleanest implementation. Pass a URL, get back parsed HTML, optionally execute JavaScript, optionally route through a residential proxy. That's the whole product.
It excels at small-to-medium volume scraping where you want to skip Puppeteer setup entirely. $49/month for 150,000 API credits.
4. ScraperAPI — high-volume sibling#
ScraperAPI competes directly with ScrapingBee and is roughly equivalent in features. Some teams prefer it for slightly cheaper bulk tiers and aggressive anti-bot defaults. If you scrape Amazon, Google, or other heavily protected targets at volume, run a 1,000-URL benchmark on both and pick whichever has a higher success rate for your URLs.
5. Octoparse — best no-code visual scraper#
Not every team has a Python developer. Octoparse lets analysts and ops people point-and-click their way through a target site, define extraction rules in a visual editor, then schedule the runs in the cloud. It's the easiest 80legs alternative for non-developers.
The free tier covers 10 tasks; paid plans start at $89/month. JavaScript rendering and IP rotation are included on the standard tier.
6. ParseHub — visual scraping for analysts#
ParseHub is Octoparse's main rival in the no-code visual category. It handles infinite scroll, dropdowns, and form submission more gracefully than Octoparse in our tests, but the entry price is higher at $189/month. Pick by interface preference — both are mature.
7. Zyte (Scrapy Cloud) — best for Python teams#
If your team already writes Scrapy spiders, Zyte is a no-brainer. It's run by the maintainers of the Scrapy framework, hosts your spiders on managed cloud infrastructure, and integrates Smart Proxy Manager (formerly Crawlera) for automatic proxy rotation. Pay per "Scrapy Cloud unit" — roughly $9 per concurrent crawler.

8. Tomba — when you're scraping for B2B contact data#
Here is the uncomfortable truth: most people who set up scrapers like 80legs are doing it to get email addresses. They scrape company websites, parse contact pages, run regex over the HTML, then verify the results.
That entire pipeline already exists as a managed API. Tomba's email finder returns verified professional emails from a domain or a name, an email verifier cleans your list, domain search returns every public email associated with a company, and data enrichment fills in titles, LinkedIn, and phone numbers from a single input.
Compared to maintaining a 80legs-style crawler, you save:
- The proxy bill ($200+/mo for residential)
- The anti-bot arms race (Cloudflare changes their fingerprinting every few months)
- The verification step (Tomba returns deliverability scores; scraped emails are guesses)
- Engineering hours (a working scraper-plus-verifier pipeline is at least two weeks of work)
Tomba starts at $49/month with a free tier of 25 searches. If your "scraping" was always about reaching humans, this is the answer.
9. Clearbit — pure enrichment#
Clearbit (now part of HubSpot) is the heavyweight in B2B enrichment. Feed it a company domain, get back firmographic, technographic, and contact data. Pricing is custom and not cheap. It's worth comparing alongside Tomba — see our Clearbit alternative breakdown for the head-to-head.
How do these 80legs alternatives compare on real workloads?#
The right pick depends entirely on what you're crawling and why. Three common scenarios:
Scenario A — Price monitoring on 50 e-commerce sites, daily. Apify or ScrapingBee. Both handle JS rendering and proxy rotation cheaply at this volume.
Scenario B — Pulling 2M product pages a week with strict anti-bot evasion. Bright Data is the only practical pick. Zyte is a viable second if your team writes Scrapy.
Scenario C — Building a sales prospecting list of 10,000 SaaS companies with founder emails. Skip scraping entirely. Use Tomba's bulk email finder or domain search to pull the data directly. A scraper here is the wrong tool — you're trying to assemble a B2B database from scratch when one already exists.
Is 80legs ever the right choice?#
For one narrow case: small academic crawls where you control the seed list, the target sites have no bot defenses, and budget matters more than reliability. Even then, Apify's free tier is competitive.
For commercial scraping, Tomba's data sources or one of the platforms above will outperform 80legs on every axis that matters in 2026 — uptime, anti-bot, proxy quality, JS support, scheduling, and customer support.
What about cost? A realistic monthly breakdown#
For a hypothetical workload of 500,000 pages scraped per month with JavaScript rendering on roughly 30% of pages, here's what you'd spend in 2026:
| Tool | Estimated monthly cost | Notes |
|---|---|---|
| 80legs | $99 (per URL plan) | Excludes proxies, captchas — you bring your own |
| Apify | $99–$199 | Depends on compute units consumed |
| Bright Data | $700–$1,200 | Includes residential proxies |
| ScrapingBee | $249 | 1M credits, 5 credits per JS page |
| ScraperAPI | $249 | Comparable to ScrapingBee |
| Zyte | $120–$250 | With Smart Proxy Manager added |
| Tomba (if data goal) | $99 | 5,000 email finder requests, includes verification |
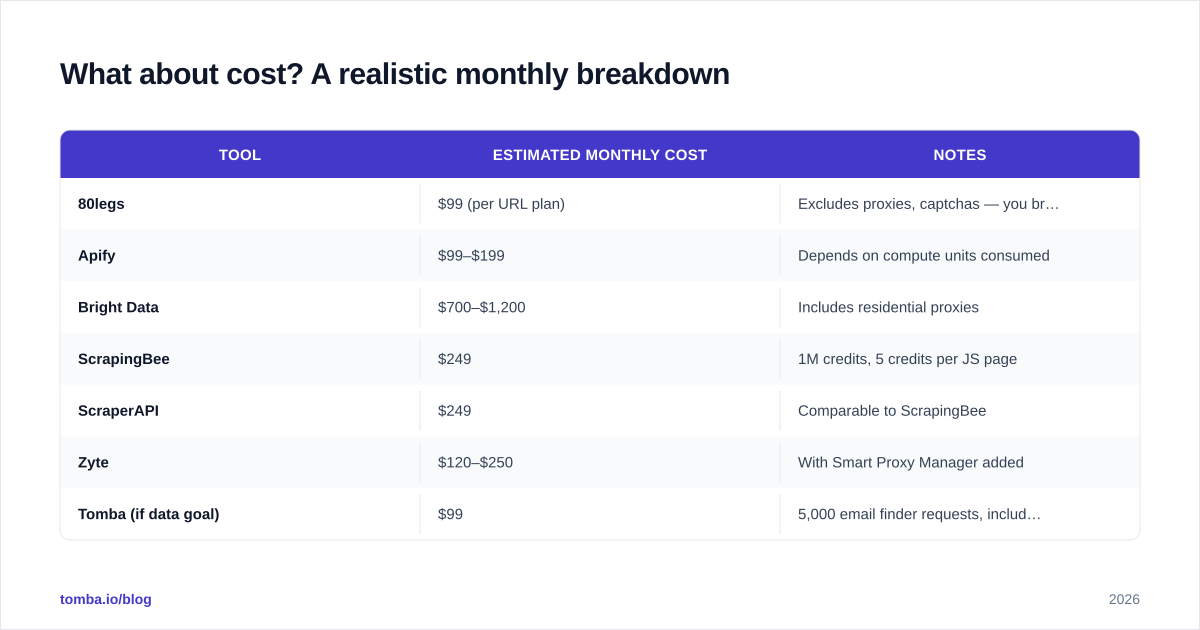
The cheapest option on paper is rarely the cheapest in practice. 80legs and self-hosted Scrapy hide the cost in your engineering team's time. A managed alternative usually wins once you account for the developer hours saved.
How do you migrate off 80legs without breaking your pipeline?#
The migration is straightforward if you treat it as a three-step swap:
- Inventory your existing crawls. Export the seed URLs, the extraction rules (XPath/CSS selectors), and the output destinations. 80legs lets you download these from the dashboard.
- Pick a target tool per crawl, not per company. It's normal to send 80% of your jobs to Apify and the remaining 20% (the heavily protected ones) to Bright Data.
- Run both in parallel for two weeks. Compare success rates, output schema diffs, and total cost. Decommission 80legs only after you've validated parity.
For the contact-data slice of your pipeline, swap regex-on-HTML for a real API. The Tomba API accepts a domain or name and returns structured, verified contacts — and it integrates with HubSpot, Pipedrive, Salesforce, and Zapier without custom code.
Final pick: which 80legs alternative should you choose?#
- Replacing 80legs as a general crawler: Apify.
- Scraping at enterprise scale with strict anti-bot: Bright Data.
- Just need an HTML-fetching API: ScrapingBee or ScraperAPI — flip a coin.
- Non-developer team: Octoparse for cheaper, ParseHub for richer flows.
- Scrapy shop:
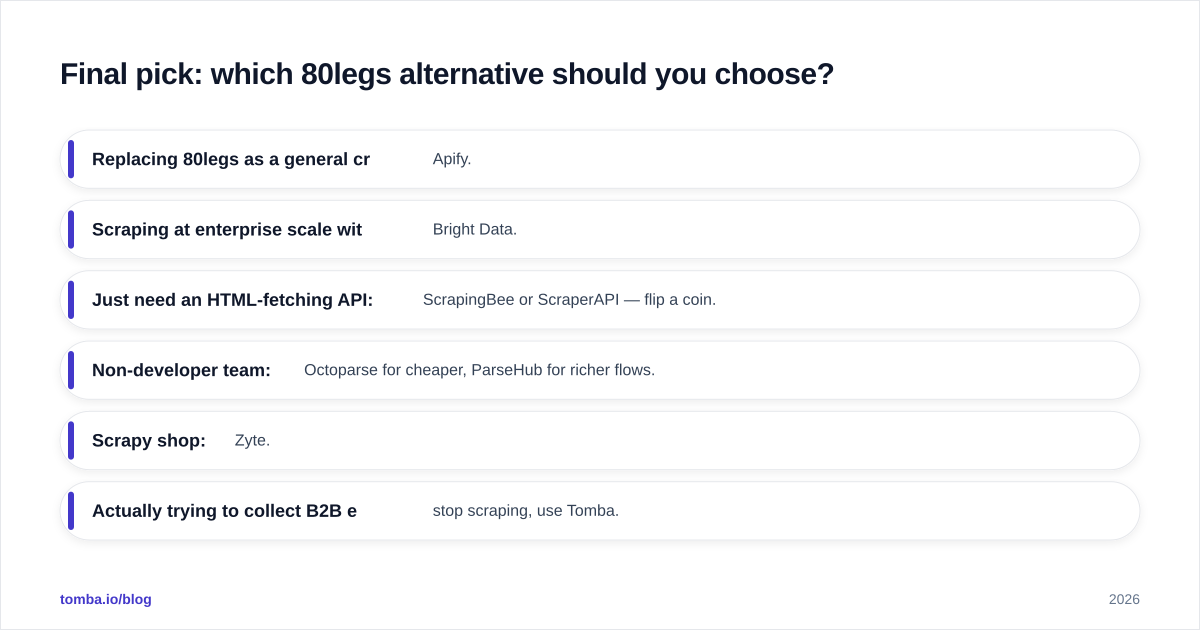
Zyte.
- Actually trying to collect B2B emails and contacts: stop scraping, use Tomba.
Ready to skip scraping for contact data?#
If your real job is finding decision-makers and their verified work emails — not maintaining a fleet of headless browsers — Tomba's email finder gives you the result in one API call instead of a six-step pipeline. Start with the free tier (25 searches), and if you outgrow it, paid plans begin at $49/month with 5,000 monthly credits and bundled verification. Skip the crawler, ship the campaign.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author