AI Lead Scoring in 2026: How It Works and Why It Wins
Manual lead scoring rewards the loudest leads, not the likeliest buyers. Here's how AI lead scoring ranks your pipeline by real conversion signals in 2026.

Most sales teams still score leads with a spreadsheet of point values somebody invented in a meeting two years ago. Job title? +10. Opened an email? +5. Downloaded a whitepaper? +15. Hit 50 points and you're "sales-ready." The problem is nobody ever checked whether those numbers predict anything. AI lead scoring throws out the guesswork and lets your historical data decide which signals actually correlate with closed deals.
This guide explains what AI lead scoring is, how it differs from the rules you're probably running today, what data it needs, and how to roll it out without lighting your pipeline on fire.
TL;DR#
- AI lead scoring uses machine learning on your historical CRM data to predict which leads are most likely to convert, instead of relying on hand-assigned point values.
- It beats manual scoring because it weighs hundreds of signals at once, updates as buying behavior shifts, and surfaces patterns humans never spot.
- It needs three data inputs: firmographics, behavioral activity, and clean contact data — and the third is where most models quietly fail.
- Expect a 6–8 week ramp: gather labeled data, train, validate against held-out deals, then run it shadow-mode beside your old scores before you trust it.
- Garbage in, garbage out. A model trained on stale emails and duplicate records will rank noise. Verified, enriched contact data is the foundation.
What is AI lead scoring?#
AI lead scoring is a system that assigns each lead a conversion-probability score using a machine-learning model trained on your own won-and-lost deal history. Instead of a human deciding "VP title = 10 points," the model looks at every lead that ever closed, finds the attributes those winners shared, and weights them automatically.
Think of it like a seasoned sales rep who has personally worked 50,000 deals and remembers every one. That rep doesn't consult a point sheet — they glance at a lead and instantly sense "this one's real." AI lead scoring is that instinct, made explicit, consistent, and scalable across your whole pipeline. Technically, it's a supervised classification or regression model (often gradient-boosted trees or logistic regression) that outputs a probability between 0 and 1.
The output usually maps to a grade (A/B/C/D) or a 0–100 score your reps and routing rules can act on. The key shift: the weights are learned, not declared.
How is AI lead scoring different from traditional rule-based scoring?#
Traditional scoring is a static rulebook. Someone sits down, assigns points to attributes and actions, sets a threshold, and that logic stays frozen until a human edits it. It feels objective because it's numeric, but every number in it is a guess.
AI lead scoring is dynamic and evidence-based. Here's the practical contrast:
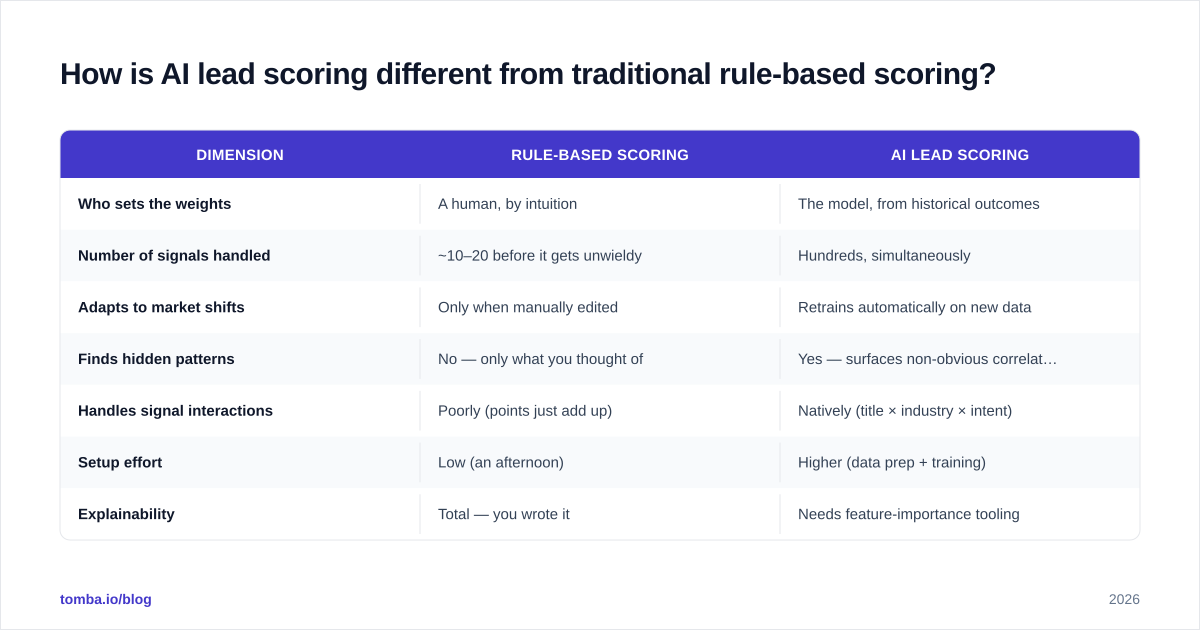
| Dimension | Rule-Based Scoring | AI Lead Scoring |
|---|---|---|
| Who sets the weights | A human, by intuition | The model, from historical outcomes |
| Number of signals handled | ~10–20 before it gets unwieldy | Hundreds, simultaneously |
| Adapts to market shifts | Only when manually edited | Retrains automatically on new data |
| Finds hidden patterns | No — only what you thought of | Yes — surfaces non-obvious correlations |
| Handles signal interactions | Poorly (points just add up) | Natively (title × industry × intent) |
| Setup effort | Low (an afternoon) | Higher (data prep + training) |
| Explainability | Total — you wrote it | Needs feature-importance tooling |
| Failure mode | Slowly drifts out of date | Breaks loudly if data quality drops |
The biggest difference isn't accuracy — it's that AI lead scoring captures interactions. A rule says "director = 8 points" everywhere. A model learns that a director at a 200-person SaaS company who visited your pricing page twice is worth far more than a director at a 5-person agency who downloaded one ebook. Additive points can't express that. A model does it by default.

That said, rule-based scoring isn't worthless. If you have fewer than a few hundred closed deals, you don't have enough labeled data to train a reliable model, and a sensible rulebook will outperform an overfit one. AI lead scoring earns its keep at volume.
What data does AI lead scoring need?#
Three categories, and a model is only as good as the weakest one.
1. Firmographic data — the company attributes: industry, employee count, revenue, tech stack, location, funding stage. This is where your ideal-customer-profile signal lives. If you sell to mid-market fintech, the model needs to see company size and industry to learn that pattern.
2. Behavioral data — what the lead actually did: pages visited, emails opened, demo requests, content downloaded, time on pricing page, product trial activity. Intent shows up here. Behavioral signals are usually the strongest predictors because they reflect active buying motion, not just fit.
3. Contact data — the identity layer: a valid email, correct name, real title, working phone. This sounds boring, but it's the silent killer. If 30% of your records have outdated titles or dead email addresses, the model trains on noise and you'll route real buyers to the trash. Clean, verified contact data is the foundation everything else sits on — which is why teams pair scoring with an email verifier and ongoing data enrichment before they ever train a model.
A useful mental model: firmographics tell you who fits, behavior tells you who's interested, and contact data tells you whether you can even reach them. Score a lead high on the first two and zero on the third and you've ranked a ghost.
How do you build an AI lead scoring model?#
You don't need a data-science PhD, but you do need discipline. Here's the realistic sequence.
Step 1 — Define the label. Decide what "converted" means. Closed-won? Became an SQL? Booked a meeting? The model predicts whatever you label, so pick the outcome that actually matters to revenue. Vague labels produce vague scores.
Step 2 — Assemble the training set. Pull every lead from the last 12–24 months with its outcome attached. You want both winners and losers — a model that only sees wins learns nothing about what disqualifies a lead. Aim for at least a few hundred examples per class.
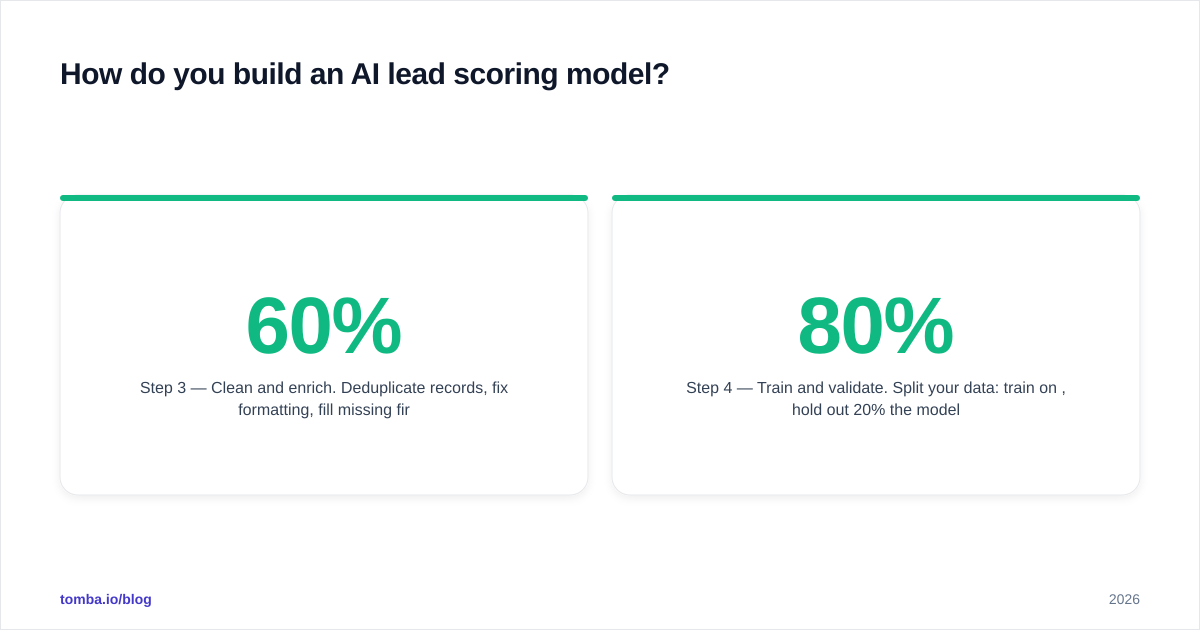
Step 3 — Clean and enrich. Deduplicate records, fix formatting, fill missing firmographic fields, and verify emails. This is the unglamorous 60% of the work. Run your list through bulk verification so dead contacts don't poison the signal.
Step 4 — Train and validate. Split your data: train on 80%, hold out 20% the model never sees. Then check whether its predictions on that held-out set match reality. If it scores held-out winners high and losers low, you have something. If not, your features are weak or your data is dirty.
Step 5 — Shadow-run before you trust it. Run the new score alongside your existing scores for 4–6 weeks without changing routing. Compare. Did the AI score predict the deals that actually closed better than your old rules? Only flip the switch once it earns it.
Step 6 — Monitor and retrain. Buying behavior drifts. Markets change. Schedule a retrain (monthly or quarterly) and watch for score drift. A model is a living asset, not a one-time project.
If you'd rather not build from scratch, many CRMs and platforms — HubSpot's predictive lead scoring, Salesforce Einstein, and others — ship managed AI scoring you can configure. The trade-off is less control over features in exchange for far less setup.
What are the common mistakes that break AI lead scoring?#
The model rarely fails because the math is wrong. It fails for boringly human reasons.
Training on dirty data. The number-one cause. Duplicate leads, stale titles, and bounced emails teach the model false patterns. Fix the data layer first or nothing downstream works.
Too little history. Fewer than ~300–500 labeled examples and the model overfits — it memorizes your training set and flops on new leads. At that scale, stick with rules.
Optimizing the wrong label. Train on "MQL" when you care about revenue and you'll get a model that's brilliant at predicting form fills and useless at predicting money.
Set-and-forget. A model trained on 2024 behavior degrades by 2026. Without retraining, AI lead scoring quietly becomes as stale as the rulebook it replaced.
No human override. Reps lose trust fast if a score is wrong and they can't flag it. Keep a feedback loop so reps can mark "this score is off" and feed that back into training.

There's a temptation to chase the shiniest new scoring tool every quarter. Resist it. The score is only as good as the data feeding it — switching vendors won't fix a contact database full of bounces. Get the foundation right and almost any competent model performs well.
Is AI lead scoring worth it for small teams?#
It depends on volume, not headcount. The honest answer:
| Scenario | Recommendation |
|---|---|
| < 300 closed deals total | Use rule-based scoring; not enough data to train |
| 300–1,000 deals, growing fast | Start with your CRM's built-in predictive scoring |
| 1,000+ deals, high lead volume | Custom AI lead scoring pays off clearly |
| High deal value, low volume | Skip scoring; score manually, it's cheap per lead |
| High volume, low deal value | AI scoring is essential — you can't manually triage |
The economic logic is simple: AI lead scoring saves rep time by routing the best leads first. If you only get 20 leads a month, a rep can eyeball all of them and scoring saves nothing. If you get 2,000, your reps are guessing, and a model that even modestly improves prioritization returns its cost many times over.
For teams sitting at the threshold, the smart move is to nail data hygiene now — verified emails, enriched firmographics, deduplicated records — so that when you cross into model territory, your training data is already clean. You can track your response rate and conversion patterns in the meantime to understand which signals matter for your business.
How does contact data quality affect AI lead scoring accuracy?#
It's the difference between a model that ranks buyers and one that ranks noise. Independent reviews on platforms like G2 consistently flag data quality — not algorithm choice — as the top reason scoring projects underperform.
Here's the chain reaction when contact data is bad:
- A lead's title is outdated → the model misreads seniority → fit score is wrong.
- The email is dead → behavioral signals never arrive → the lead looks "cold" when it's actually unreachable.
- Duplicate records split one buyer's activity across two profiles → both look low-intent.
- The model trains on all of the above → it learns garbage → it confidently ranks garbage.
This is why the most overlooked step in any scoring rollout is the enrichment and verification layer. Before a lead ever hits the model, you want its email validated, its company data filled in, and duplicates collapsed. Tools like the Tomba Email Finder and domain search close the gaps in your contact records, and a catch-all verifier handles the tricky domains that wreck deliverability scores. Get this layer right and your model's accuracy climbs without touching a single line of model code.
What's the future of AI lead scoring in 2026 and beyond?#
Three shifts are already underway.
Real-time scoring. Instead of nightly batch jobs, scores update the instant a lead acts. Visit the pricing page, your score jumps, and the lead routes to a rep within seconds.
Intent-data fusion. Models increasingly blend first-party behavior with third-party intent signals — what a company is researching across the web — for earlier, sharper predictions.
Explainability as a default. "Why is this lead an A?" used to be hard to answer. Newer tooling surfaces the top three reasons behind every score, which rebuilds rep trust and makes scoring auditable.
Generative follow-up. Once a lead is scored, AI increasingly drafts the right outreach for that score tier automatically, tightening the loop from prediction to action.
The throughline across all of it: scoring is getting faster and more automated, which makes the quality of the underlying data more important, not less. A real-time model fed bad emails just makes wrong decisions faster.
The bottom line#
AI lead scoring wins when you have the volume to train it and the data discipline to feed it. It replaces a rulebook full of guesses with weights learned from your actual deal history, captures signal interactions humans can't track, and adapts as your market moves. But every advantage it offers collapses if the contact data underneath is stale, duplicated, or unverified.
Start with the foundation. Before you train a single model, make sure the leads in your CRM have verified emails, complete firmographics, and no duplicates. The fastest way to do that is to find and validate contact data at the source — the Tomba Email Finder pulls accurate professional emails by name, domain, or company so your scoring model trains on real, reachable buyers instead of noise. Pair it with verification and enrichment, and whatever model you run on top will reward you with rankings you can actually trust. Try it on your next list and watch your A-grade leads turn into booked meetings.
Ready to find emails that actually work?
Join 150,000+ professionals who stopped guessing and started sending. Free credits on signup — no credit card required.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author