AI Pipeline Inspection in 2026: A Sales Manager's Playbook
Gut-feel deal reviews are dying. Here's how AI pipeline inspection scores deal health, flags slipping deals, and makes your forecast something you can actually defend in 2026.

TL;DR
- AI pipeline inspection replaces gut-feel deal reviews with signal-based scoring: it reads CRM activity, email and call engagement, and deal velocity to rank every open opportunity by real health.
- It catches slipping deals weeks earlier than a Monday pipeline meeting, and it kills "happy ears" forecasting where reps call commit on deals with no buyer momentum.
- The biggest accuracy lever isn't the AI model — it's clean, complete contact and activity data feeding it. Garbage in, confident-sounding garbage out.
- You don't need a $100k platform to start. A scoring rubric, consistent CRM hygiene, and one enrichment source get you 80% of the value.
- This guide covers how it works, a tooling comparison, the data you need, and a 30-day rollout plan.
What is AI pipeline inspection?#
AI pipeline inspection is the practice of using machine learning to evaluate the health of every open deal in your pipeline automatically, instead of relying on what reps say in a weekly forecast call.
Think of it like a car's check-engine system. For decades, you drove until something broke, then guessed at the cause. Pipeline inspection used to work the same way: a deal died, and the manager asked "what happened?" after the fact. AI inspection is the dashboard light that flashes before the engine seizes — it reads dozens of signals continuously and tells you which deals are about to stall while you can still do something about them.
Technically, the system ingests structured and unstructured signals — CRM stage history, email open and reply rates, meeting cadence, call sentiment, number of contacts engaged at the account, and time-in-stage — then outputs a health score and a predicted close probability for each opportunity. Most platforms layer this on top of your existing CRM rather than replacing it.
The shift matters because human forecasting is biased. Reps are optimists by selection. Managers anchor on the loudest deal in the room. AI scoring is boring, consistent, and immune to a charismatic rep talking up a deal that hasn't had a buyer reply in three weeks.
Why are gut-feel pipeline reviews failing in 2026?#
Because buying committees got bigger and slower while sales teams got leaner. The average B2B deal now involves multiple stakeholders, and a single champion's enthusiasm tells you almost nothing about whether the economic buyer is on board.
Three failure modes show up again and again:
- Happy ears. A rep had a great call, so the deal is "looking good." Great calls are not signed contracts. Without engagement data across the account, you're forecasting on vibes.
- The zombie deal. It's been in "Negotiation" for 90 days. Nobody wants to mark it lost because that hurts the number, so it haunts the pipeline and inflates the forecast quarter after quarter.
- The hidden gem. A quiet, well-qualified deal with strong multi-threaded engagement gets ignored because the rep didn't flag it, and it slips because nobody prioritized it.
AI inspection attacks all three by looking at behavior, not narrative. According to Gartner's research on sales technology, organizations that operationalize data-driven deal inspection consistently report more accurate forecasts than those running manual reviews.

How does AI score deal health?#
It weighs signals into a single score. The exact weights vary by vendor and by your own historical win/loss data, but the input categories are consistent.
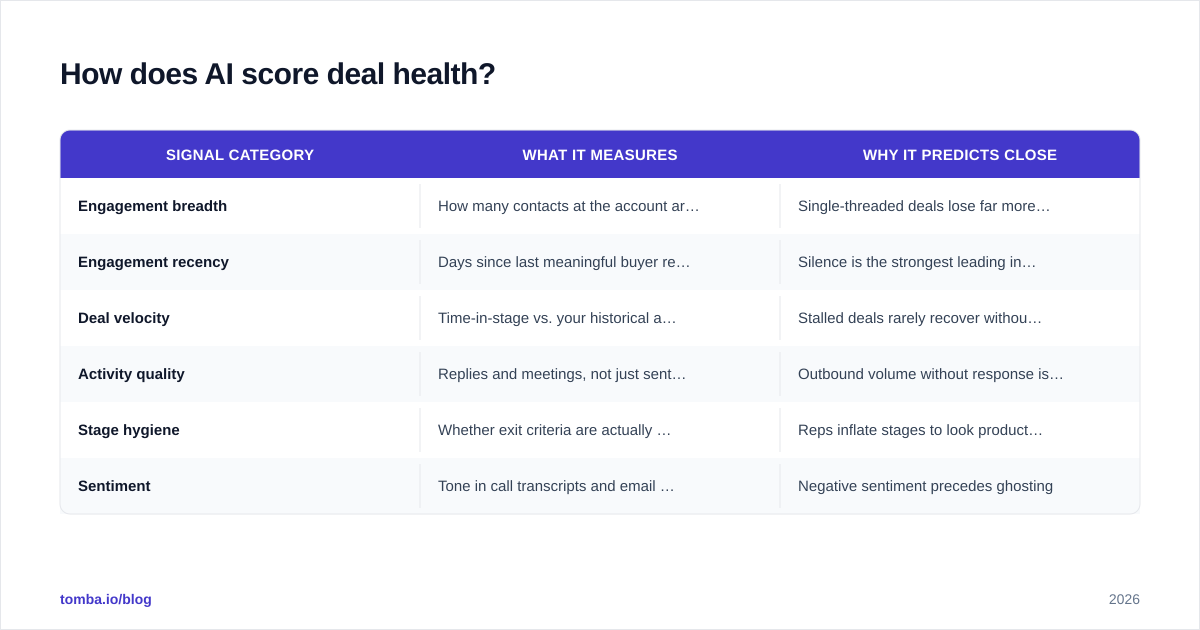
| Signal category | What it measures | Why it predicts close |
|---|---|---|
| Engagement breadth | How many contacts at the account are active | Single-threaded deals lose far more often |
| Engagement recency | Days since last meaningful buyer reply | Silence is the strongest leading indicator of slippage |
| Deal velocity | Time-in-stage vs. your historical average | Stalled deals rarely recover without intervention |
| Activity quality | Replies and meetings, not just sent emails | Outbound volume without response is noise |
| Stage hygiene | Whether exit criteria are actually met | Reps inflate stages to look productive |
| Sentiment | Tone in call transcripts and email threads | Negative sentiment precedes ghosting |
The model compares each live deal against patterns from your closed-won and closed-lost history. A deal that looks like 200 deals you lost gets a low score regardless of how confident the rep feels.
One critical dependency: the engagement-breadth signal only works if you actually have contact records for the full buying committee. If your CRM has one contact per account, the AI is blind to the most predictive signal you have. This is where pulling in the rest of the committee — using a domain search to find the other decision-makers at the account — directly improves inspection accuracy.
What data do you need to feed it?#
Clean, complete, and current data — in that order of importance. The model is only as good as the signals reaching it, and most pipeline-inspection failures trace back to thin data rather than a weak algorithm.
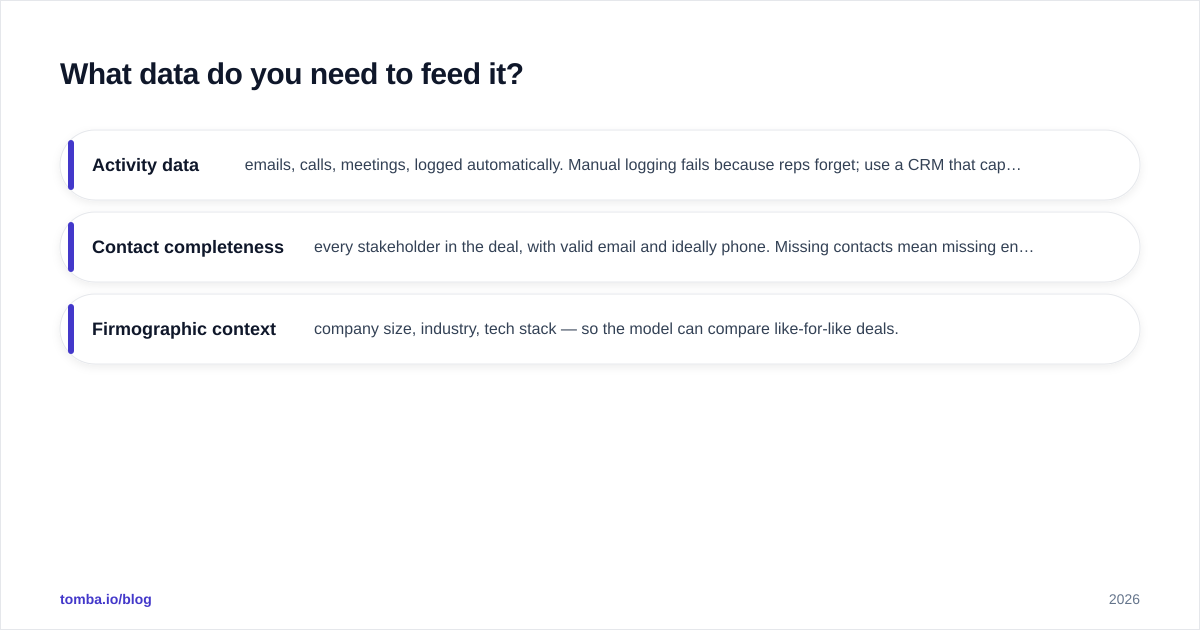
You need three layers:
- Activity data — emails, calls, meetings, logged automatically. Manual logging fails because reps forget; use a CRM that captures activity passively.
- Contact completeness — every stakeholder in the deal, with valid email and ideally phone. Missing contacts mean missing engagement signals.
- Firmographic context — company size, industry, tech stack — so the model can compare like-for-like deals.
Contact completeness is where most teams quietly lose accuracy. If a rep is working a 6-person buying committee but only 2 are in the CRM, your inspection tool thinks the deal is single-threaded and scores it low — or worse, scores it high because the 2 known contacts are engaged. Backfilling the committee with verified contacts changes the score materially. Tools like the Tomba Email Finder and a solid email verifier keep those records valid so the engagement signal reflects reality, not a stale snapshot. Bounced emails to dead contacts also drag down your sender reputation, which quietly suppresses the very engagement data the model relies on.

AI pipeline inspection tools compared#
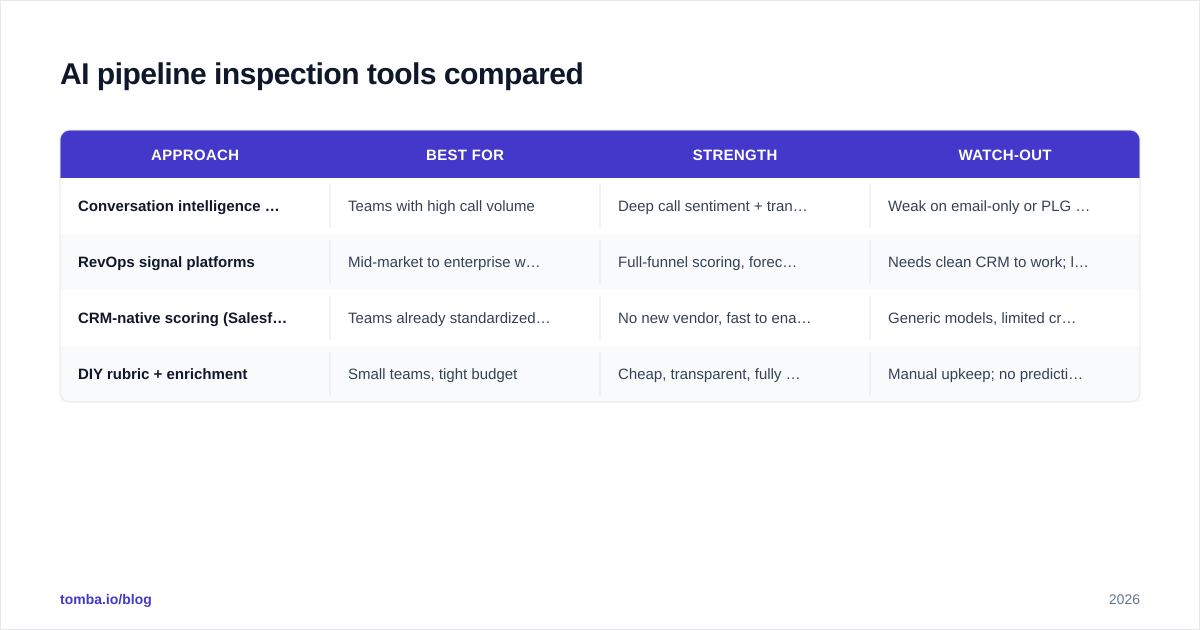
The market splits into three tiers. Conversation-intelligence platforms inspect via call data, RevOps platforms inspect via CRM signals, and lightweight scoring layers bolt onto your existing stack. Here's an honest comparison of the categories.
| Approach | Best for | Strength | Watch-out |
|---|---|---|---|
| Conversation intelligence (e.g., Gong) | Teams with high call volume | Deep call sentiment + transcript analysis | Weak on email-only or PLG motions; premium pricing |
| RevOps signal platforms | Mid-market to enterprise with mature CRM | Full-funnel scoring, forecasting | Needs clean CRM to work; long onboarding |
| CRM-native scoring (Salesforce, HubSpot) | Teams already standardized on one CRM | No new vendor, fast to enable | Generic models, limited cross-source signals |
| DIY rubric + enrichment | Small teams, tight budget | Cheap, transparent, fully owned | Manual upkeep; no predictive ML |
For most teams under 50 reps, starting CRM-native makes sense. HubSpot's deal-management features and Salesforce's Einstein scoring both ship inspection capabilities you may already own. Layer richer contact data on top — pulled via the Tomba API or a HubSpot integration — and you've covered the data gap that breaks native models.
If you want to read peer reviews before committing to a dedicated platform, G2's sales analytics category is a reasonable neutral starting point.
How do you run an inspection cadence that sticks?#
Make it a routine, not a fire drill. The technology is useless if the team treats the scores as decoration. A workable cadence has three loops at different frequencies.
Daily (rep level). Reps see their own deal scores each morning. A deal that dropped a health tier overnight gets a next step before lunch. This is self-service — no manager needed.
Weekly (manager level). The pipeline meeting flips. Instead of walking every deal, you walk only the exceptions: high-value deals with falling scores, and high-score deals that reps aren't forecasting. You spend the hour on the 10 deals that matter, not the 80 that don't.
Monthly (RevOps level). You inspect the inspector. Are the scores calibrated against what actually closed? If deals scored "healthy" keep losing, the model needs retraining or your stage definitions are broken. This feedback loop is what separates teams that trust the system from teams that quietly abandon it.
A practical rule: never let a rep override a low score without writing one sentence of why. "Champion confirmed budget in writing" is a valid override. "I have a good feeling" is not. Those override notes become training data and a coaching record.
What are the limits and risks?#
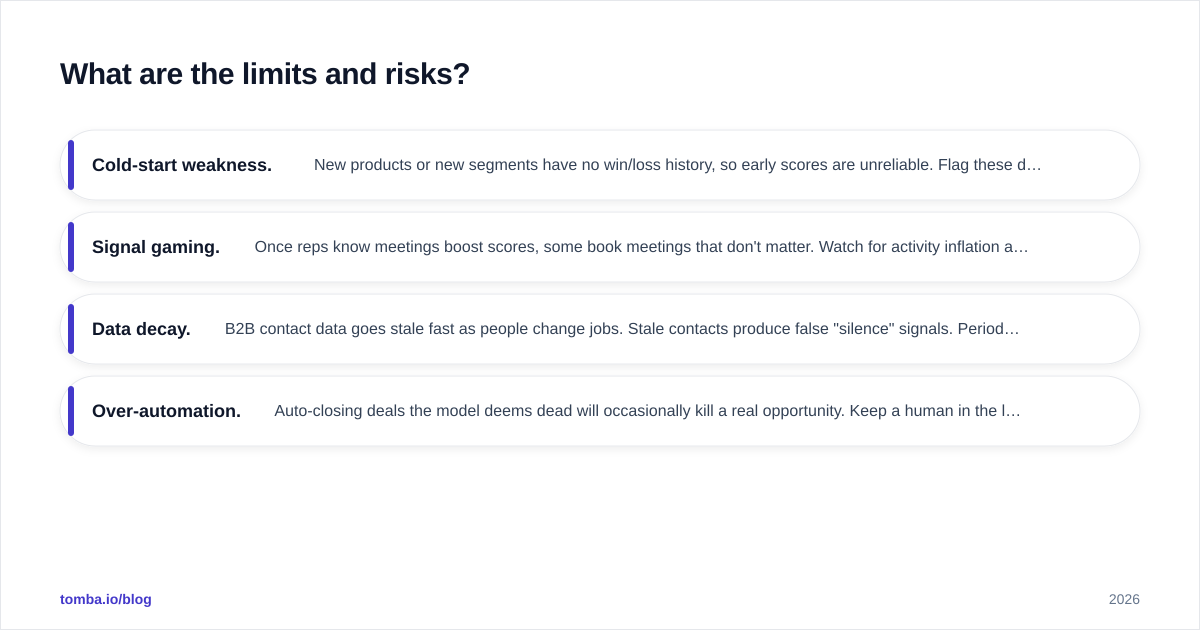
AI pipeline inspection is a decision-support tool, not an oracle — and treating it as ground truth creates new problems.
- Cold-start weakness. New products or new segments have no win/loss history, so early scores are unreliable. Flag these deals for human-only review until you have enough closed data.
- Signal gaming. Once reps know meetings boost scores, some book meetings that don't matter. Watch for activity inflation and weight reply signals over sent signals.
- Data decay. B2B contact data goes stale fast as people change jobs. Stale contacts produce false "silence" signals. Periodic re-verification and contact enrichment keep the inputs honest.
- Over-automation. Auto-closing deals the model deems dead will occasionally kill a real opportunity. Keep a human in the loop for any irreversible action.
The honest framing: AI tells you where to look. Your reps and managers still decide what to do. A team that uses scores to start better conversations wins. A team that uses scores to avoid conversations loses.
How do you roll it out in 30 days?#
Start small, prove the signal, then expand. A full-platform rollout that takes six months usually dies of CRM-hygiene problems before it shows value.
- Days 1–7: Fix the data. Audit contact completeness on your top 20 open deals. Use bulk lead generation to backfill missing committee members and verify existing emails. You'll be surprised how single-threaded "healthy" deals really are.
- Days 8–14: Define the rubric. Even if you're buying a platform, write down what you think healthy looks like. This becomes your sanity check against the model's output.
- Days 15–21: Run parallel. Score deals with the tool, but keep your old forecast too. Compare. Look for the deals where they disagree — that's where the insight is.
- Days 22–30: Flip the cadence. Run one exception-based pipeline meeting. Measure how much time you save and how many at-risk deals surface that the old review missed.
By day 30 you'll know whether the scores correlate with reality on your pipeline, which is the only proof that matters before you invest further.
The bottom line#
AI pipeline inspection works when the data underneath it is complete and clean — and it produces confident nonsense when it isn't. The model is rarely the bottleneck; the missing half of the buying committee and the bounced email addresses are. Get the contact layer right first, and even a basic scoring rubric will sharpen your forecast more than an expensive platform fed on thin data.
If your pipeline inspection is only as good as the contacts in your CRM, start by filling the gaps. The Tomba Email Finder finds and verifies the full buying committee at every account — by name, company, or domain — so your deal-health scores reflect who's actually in the deal, not just the one contact your rep happened to log. Check the Tomba pricing plans (free tier included, 25 searches a month) and feed your inspection engine the clean data it needs to earn your trust.
Ready to find emails that actually work?
Join 150,000+ professionals who stopped guessing and started sending. Free credits on signup — no credit card required.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author