AI Revenue Engine in 2026: Build a GTM Growth System
An AI revenue engine connects data, scoring, and outreach into one closed loop. Here's how to architect one in 2026 — without buying ten disconnected tools.

TL;DR
- An AI revenue engine is a closed-loop system that links data, scoring, routing, and outreach so every stage feeds the next — not a single product you buy.
- The four core layers are data foundation, intelligence (scoring and prediction), activation (outreach and sequencing), and measurement (attribution and feedback).
- The bottleneck is almost never the AI model. It's dirty contact data feeding the model garbage, which is why enrichment and verification sit at the base of the stack.
- You can assemble a working engine with 4-5 connected tools rather than a 12-vendor sprawl; the integration discipline matters more than the logo count.
- Start with one measurable loop (lead in → enriched → scored → routed → contacted → outcome logged), then expand.
What is an AI revenue engine?#
An AI revenue engine is a connected system that turns raw signals — a new signup, a website visit, a funding announcement — into pipeline and closed revenue, with machine learning making the routing and prioritization decisions in between. Think of it like a car's drivetrain: the engine (your AI models) is useless without fuel (clean data), transmission (workflow automation), and a dashboard (attribution) telling you whether you're actually moving. Remove any one part and the whole thing stalls.
The phrase gets abused. Most vendors slap "AI revenue engine" on a single feature — a lead scorer, a sequencer, a chatbot — and call it a day. That's a component, not an engine. The defining trait of a real engine is the loop: outcomes flow back into the system and change future decisions. A deal that closes teaches the scoring model what good looks like. A bounced email teaches the data layer which source to trust less.
This is squarely a revenue operations discipline. The technology is the easy part; the hard part is wiring the layers so they actually talk to each other.
Why do most "AI revenue" stacks fail?#
They fail because teams buy intelligence before they fix the data underneath it. An AI scoring model trained on contact records that are 30% stale, 15% duplicated, and missing job titles will confidently produce wrong priorities — and your reps will learn to ignore it within a quarter. Gartner has repeatedly flagged poor data quality as a primary reason analytics and AI initiatives underdeliver, and revenue tooling is no exception (gartner.com).
The second failure mode is sprawl. A team buys a data vendor, a separate enrichment tool, a scoring platform, a sequencer, and a CRM add-on — none of which share a contact ID. The "engine" becomes five tabs a human copy-pastes between. That's not automation; it's a more expensive manual process.
)
Here's the uncomfortable truth: the model tier barely matters once the data is clean and the loop is closed. Whether you use a frontier LLM or a simple logistic regression for lead scoring, both beat a human guessing — if the inputs are accurate. Spend your budget on the foundation first.
What are the core components of an AI revenue engine?#
Four layers, in order of dependency. Lower layers must work before upper layers add value.
1. Data foundation. Accurate contact and account records: emails, phone numbers, job titles, firmographics, and intent signals. This is the fuel. If you can't reliably find and verify a decision-maker's email, nothing downstream works. Tools like the Tomba Email Finder and an email verifier sit here, alongside data enrichment that fills gaps in your existing CRM rows.
2. Intelligence. Lead scoring, propensity-to-buy models, churn prediction, and next-best-action. This layer ranks and routes. It only deserves trust when layer 1 is solid.
3. Activation. Sequencing, personalization, channel selection — turning a scored lead into an actual touch. AI drafts the first email, picks the send time, and adapts based on replies.
4. Measurement. Attribution and the feedback loop. Every outcome — opened, replied, booked, closed, lost — flows back to retrain scoring and reweight data sources. Without this layer you have automation, not an engine.
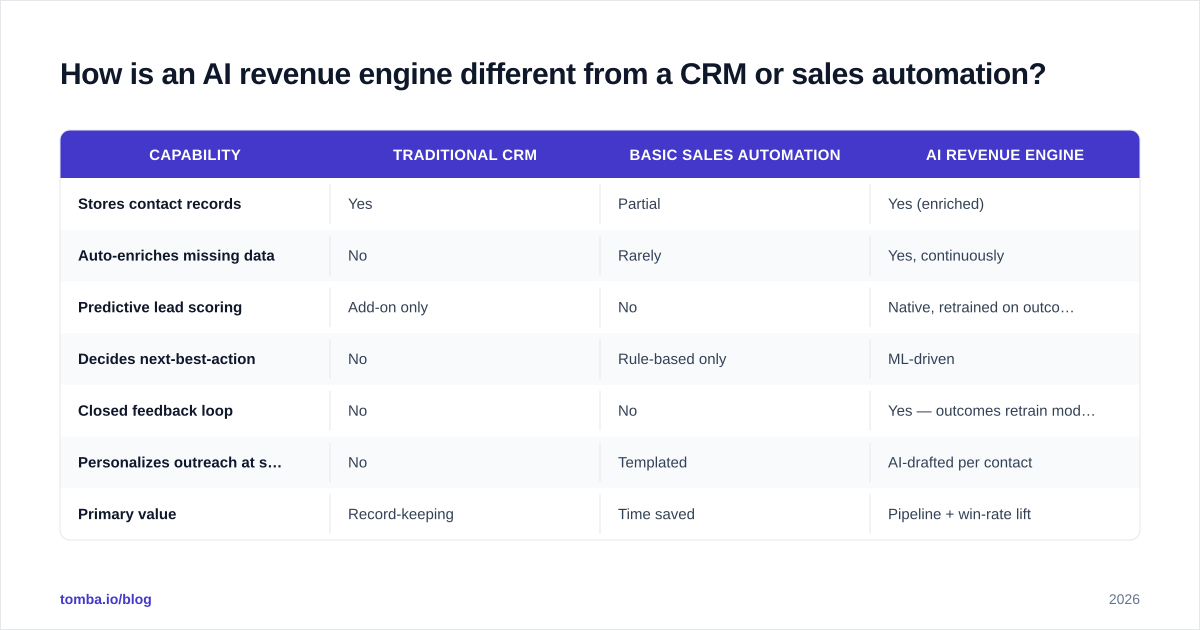
How is an AI revenue engine different from a CRM or sales automation?#
A CRM is the system of record; an AI revenue engine is the system of decision. The CRM stores what happened. The engine decides what should happen next and acts on it. They're complementary — your engine reads from and writes to the CRM — but they are not the same thing.
| Capability | Traditional CRM | Basic sales automation | AI revenue engine |
|---|---|---|---|
| Stores contact records | Yes | Partial | Yes (enriched) |
| Auto-enriches missing data | No | Rarely | Yes, continuously |
| Predictive lead scoring | Add-on only | No | Native, retrained on outcomes |
| Decides next-best-action | No | Rule-based only | ML-driven |
| Closed feedback loop | No | No | Yes — outcomes retrain models |
| Personalizes outreach at scale | No | Templated | AI-drafted per contact |
| Primary value | Record-keeping | Time saved | Pipeline + win-rate lift |
The distinction matters when you budget. Adding an "AI" checkbox to your existing CRM gives you a scorer, not an engine. The engine is the orchestration across all four layers.
How do you build an AI revenue engine in 2026?#
Build one loop, prove it, then widen it. Resist the urge to architect all four layers at once.
Step 1 — Fix the fuel. Audit your contact data. Run your existing list through a bulk email finder and verification pass. Establish where your data comes from and how fresh it is; Tomba documents its data sources so you can reason about coverage and recency. Set a quality bar: bounce rate under 3%, title coverage above 80%.
Step 2 — Add a single intelligence signal. Don't boil the ocean. Pick one score — say, fit (does this account match your ICP?) — and route high-fit leads to reps faster. Measure whether routed leads convert better than the control.
Step 3 — Automate one activation path. AI-draft the first-touch email for that high-fit segment. Keep a human approving sends until reply rates hold steady. Connect the data layer directly to outreach via the Tomba API or a no-code path like Zapier so enriched contacts flow into sequences without copy-paste.
Step 4 — Close the loop. Pipe outcomes back. When a sequence books a meeting, that's a positive label. When an email hard-bounces, downrank that data source. This feedback is what turns a pile of tools into an engine.
)
Step 5 — Widen. Add phone as a channel with a phone finder, layer in intent signals, expand scoring to propensity. Each addition is a new loop you validate before trusting.
The discipline is integration, not acquisition. Five tools that share a contact ID and pass outcomes back to each other beat twelve best-of-breed point solutions that don't.
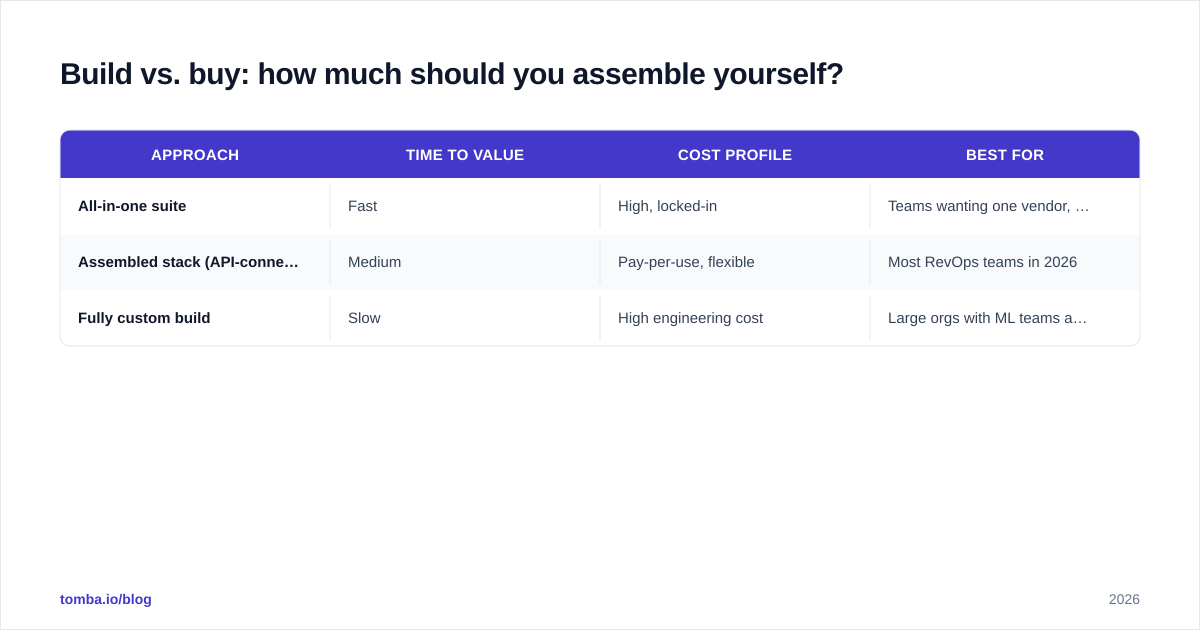
Build vs. buy: how much should you assemble yourself?#
Most teams should assemble, not build from scratch. Training your own scoring model is rarely worth it before you have thousands of labeled outcomes; until then, off-the-shelf scoring plus excellent data wins. The high-leverage decision is which data foundation you standardize on, because everything upstream depends on it.
| Approach | Time to value | Cost profile | Best for |
|---|---|---|---|
| All-in-one suite | Fast | High, locked-in | Teams wanting one vendor, less control |
| Assembled stack (API-connected) | Medium | Pay-per-use, flexible | Most RevOps teams in 2026 |
| Fully custom build | Slow | High engineering cost | Large orgs with ML teams and unique data |
For the data layer specifically, usage-based pricing keeps you honest — you pay for what the engine consumes. Tomba's tiers run from a free plan (25 searches/month) through Starter at $49/mo and Growth at $99/mo up to Pro at $249/mo; full Tomba pricing scales with the volume your engine actually pulls, so you're not pre-buying capacity you don't need. Compare any vendor's effective cost-per-verified-contact, not the sticker price, since a cheap source with a 20% bounce rate poisons every layer above it.
If you're weighing platforms, third-party review sites like G2 are useful for filtering on integration depth and data accuracy rather than marketing claims.
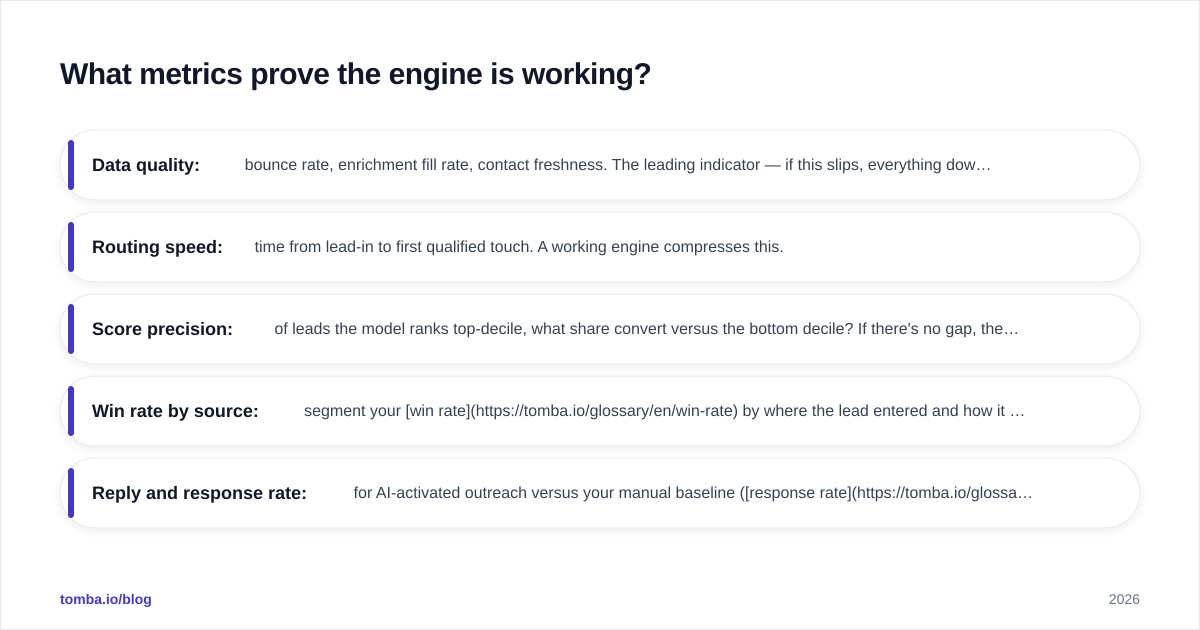
What metrics prove the engine is working?#
You're looking for lift attributable to the loop, not vanity throughput. Track these:
- Data quality: bounce rate, enrichment fill rate, contact freshness. The leading indicator — if this slips, everything downstream degrades.
- Routing speed: time from lead-in to first qualified touch. A working engine compresses this.
- Score precision: of leads the model ranks top-decile, what share convert versus the bottom decile? If there's no gap, the model isn't earning its keep.
- Win rate by source: segment your win rate by where the lead entered and how it was scored.
- Reply and response rate: for AI-activated outreach versus your manual baseline (response rate benchmarks).
If the engine can't move at least one of these against a control group, you have expensive automation, not a revenue engine. Kill the parts that don't show lift and double down on the parts that do.
Where does AI actually add value versus hype?#
AI adds the most value in ranking and drafting, the least in places teams expect magic. Prioritizing thousands of leads, predicting which accounts are heating up, and drafting a credible first email — these are genuine wins because they're high-volume judgment calls where "better than a rushed human" is an easy bar to clear.
Where the hype outruns reality: fully autonomous deal-closing, "set it and forget it" agents that need no human review, and any pitch that skips the data conversation entirely. Forrester and other analysts consistently note that AI augments revenue teams rather than replacing the judgment in late-stage deals (forrester.com). Treat any vendor promising autonomous revenue with the skepticism it deserves — and ask them what happens when the underlying data is wrong.
Conclusion: start with the fuel#
The AI revenue engine that works in 2026 isn't the one with the most models or the longest tool list. It's the one with a clean data foundation, one closed loop proven against a control, and the discipline to widen only what shows lift. Intelligence is cheap and commoditizing; accurate, verified contact data is the durable advantage that every layer above depends on.
Start there. If your reps can't reliably reach the right decision-maker, no model will save the quarter. The Tomba Email Finder gives your engine the fuel it needs — verified professional emails by name, domain, or company — with a free tier to test coverage on your own ICP before you scale. Build the foundation first, close the loop, and let the engine compound from there.
Ready to find emails that actually work?
Join 150,000+ professionals who stopped guessing and started sending. Free credits on signup — no credit card required.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author