Apify vs Scrapy 2026: Which Web Scraper Wins for B2B Data?
Apify vs Scrapy compared on speed, cost, scaling, and maintenance. See which web scraping stack fits your B2B data team in 2026 — and where a finished dataset beats both.
Choosing between Apify and Scrapy comes down to one question: do you want to own the plumbing or rent it? Scrapy is a battle-tested open-source framework you run yourself. Apify is a managed cloud platform that wraps scrapers, proxies, scheduling, and storage into one paid service. Both pull data off the web; they just put the operational burden in very different places.
This guide breaks down where each one wins, what they actually cost once you count engineering time, and when neither is the right tool for a B2B data job.
TL;DR#
- Scrapy is a free Python framework. Maximum control, zero per-request cost, but you own the proxies, servers, anti-bot fixes, and on-call pager.
- Apify is a managed platform with thousands of pre-built "Actors," rotating proxies, and scheduling baked in. You pay for compute and proxy traffic but skip most infrastructure work.
- Pick Scrapy when you have Python engineers, predictable targets, and high volume where per-request cost matters.
- Pick Apify when speed-to-data, anti-bot resilience, and low maintenance matter more than raw infrastructure cost.
- If your end goal is B2B contact data (emails, phones, firmographics), a purpose-built provider often beats building either scraper from scratch.
What is Scrapy?#
Scrapy is an open-source web crawling framework written in Python, first released in 2008 and still actively maintained. You define "spiders" — classes that describe which URLs to visit, how to parse the response, and what fields to extract. It ships with an asynchronous engine (built on Twisted), middleware hooks, item pipelines, and exporters for JSON, CSV, and XML.
The appeal is total control. Nothing about your crawl is hidden behind a dashboard. You decide concurrency, retry logic, throttling, and where the data lands. Because it's just Python, you can drop it into any CI pipeline, container, or cron job you already run.
The cost is everything Scrapy doesn't do. It does not render JavaScript out of the box (you bolt on Playwright or Splash). It does not rotate proxies for you. It does not schedule itself, store your results in a queryable place, or alert you when a target site changes its markup and your selectors break at 3 a.m. Those are your problems to solve.
What is Apify?#
Apify is a cloud platform for running web scrapers and browser automation at scale. Its core unit is the Actor — a containerized program you run on Apify's infrastructure. You can write your own Actor (Scrapy spiders run on Apify, in fact), or grab one of thousands of pre-built Actors from the Apify Store for sites like LinkedIn, Google Maps, Amazon, and Instagram.
Around that runtime, Apify bundles the operational layer most teams hate building: a residential and datacenter proxy pool, a scheduler, a request queue, dataset storage, key-value stores, webhooks, and an API. You write the extraction logic; the platform handles distribution, retries, and persistence.
In short, Scrapy gives you an engine. Apify gives you the engine plus the garage, the fuel station, and the mechanic.
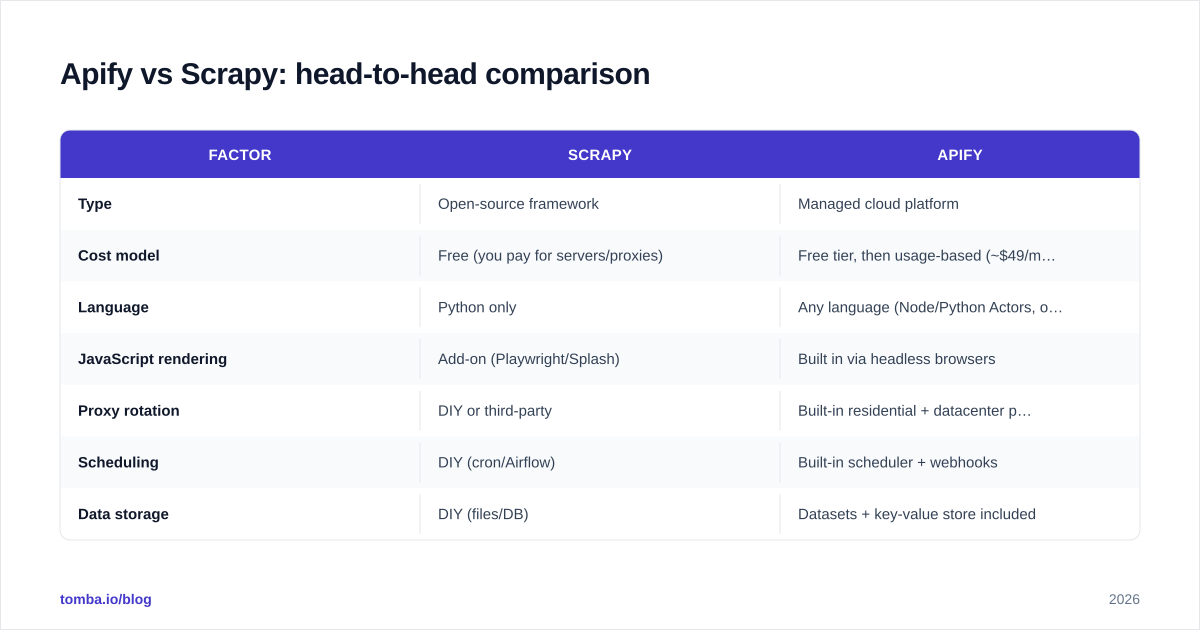
Apify vs Scrapy: head-to-head comparison#
| Factor | Scrapy | Apify |
|---|---|---|
| Type | Open-source framework | Managed cloud platform |
| Cost model | Free (you pay for servers/proxies) | Free tier, then usage-based (~$49/mo Starter and up) |
| Language | Python only | Any language (Node/Python Actors, or run Scrapy) |
| JavaScript rendering | Add-on (Playwright/Splash) | Built in via headless browsers |
| Proxy rotation | DIY or third-party | Built-in residential + datacenter pool |
| Scheduling | DIY (cron/Airflow) | Built-in scheduler + webhooks |
| Data storage | DIY (files/DB) | Datasets + key-value store included |
| Pre-built scrapers | None | Thousands of Store Actors |
| Maintenance burden | High — you own everything | Low — platform absorbs most ops |
| Best for | Engineering teams, high volume | Fast results, low ops, anti-bot-heavy sites |
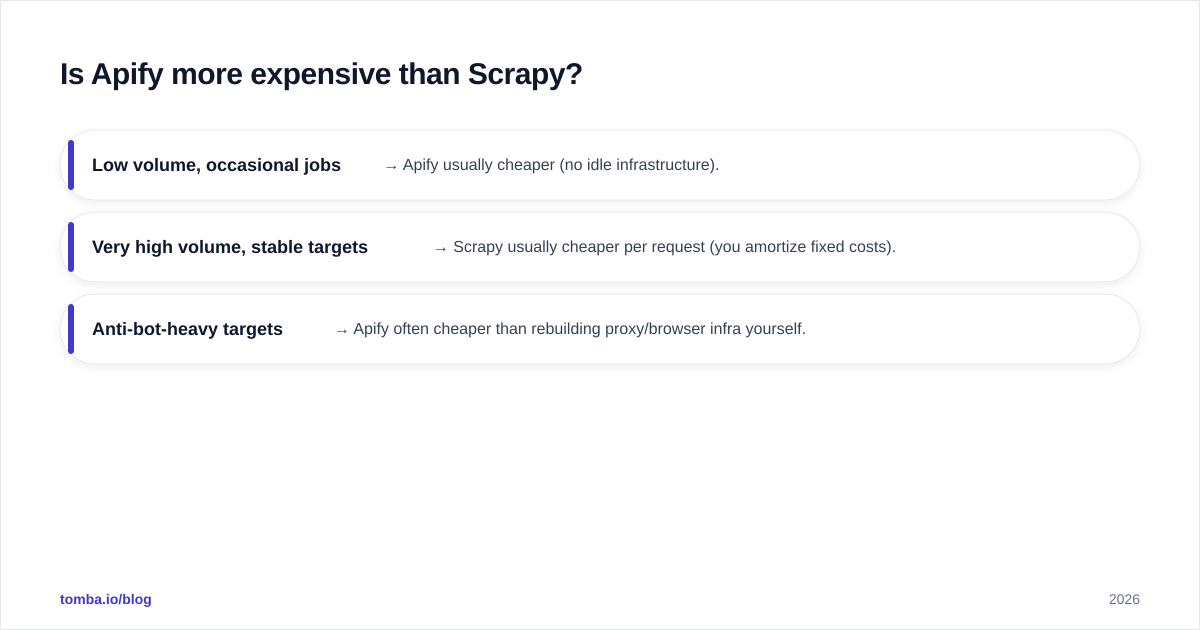
Is Apify more expensive than Scrapy?#
On paper, Scrapy is free and Apify is not. In practice the comparison is rarely that clean.
Scrapy's license costs nothing, but a production crawler needs servers, a proxy subscription (residential proxies run real money), monitoring, and — the big one — engineer hours to build and maintain it. A single mid-level engineer maintaining anti-bot workarounds and broken selectors can cost more per month than a healthy Apify bill. The "free" framework is only free if your time is.
Apify's pricing is usage-based: a free tier to start, then paid plans that scale with compute units and proxy traffic. You can blow through credits fast on JavaScript-heavy sites behind residential proxies. The upside is that the bill is a predictable line item instead of an unpredictable on-call burden.
The honest rule of thumb:
- Low volume, occasional jobs → Apify usually cheaper (no idle infrastructure).
- Very high volume, stable targets → Scrapy usually cheaper per request (you amortize fixed costs).
- Anti-bot-heavy targets → Apify often cheaper than rebuilding proxy/browser infra yourself.

Which scales better for large crawls?#
Both scale to millions of pages — the difference is who does the scaling work.
Scrapy scales horizontally if you wire it up: scrapy-redis for distributed queues, containers behind an orchestrator, and your own autoscaling rules. It's powerful and cheap at scale, but it's a project. You'll spend real time on deduplication, backpressure, and failure recovery.
Apify scales by design. Actors run in parallel containers, the request queue handles distribution, and autoscaling adjusts to load without you touching it. You trade fine-grained control for the platform doing the hard parts. For teams without dedicated infra engineers, that trade is usually worth it.
If your crawl targets are stable and you have the Python talent, Scrapy at scale is hard to beat on unit economics. If your targets fight back with bot detection and your team is small, Apify's managed scaling pays for itself.
How do they handle anti-bot and JavaScript-heavy sites?#
This is where many Scrapy projects quietly die. Modern sites render content with JavaScript and deploy detection (Cloudflare, DataDome, fingerprinting). Vanilla Scrapy fetches raw HTML and sees an empty shell.
You can fix this — scrapy-playwright renders pages, and a paid proxy service rotates IPs — but now you're maintaining a browser automation stack and a proxy budget on top of your spiders. Every time a target updates its defenses, you patch.
Apify treats this as a first-class problem. Headless Chromium is built in, its proxy pool includes residential IPs, and the platform offers fingerprint and session management to look like real traffic. Pre-built Store Actors for tough targets are maintained by their authors, so the anti-bot arms race isn't entirely your fight.
For a deep comparison of approaches, the G2 web scraping category lists how dozens of tools position on this exact axis.
When should you use Scrapy over Apify?#
Reach for Scrapy when:
- You have Python engineers who will own the crawler long-term.
- Your targets are stable and don't aggressively block bots.
- Volume is high enough that per-request platform fees would dominate.
- You need the crawler embedded in existing infrastructure with no external dependency.
- Data residency or compliance rules forbid sending traffic through a third-party platform.
Scrapy rewards teams that treat scraping as core infrastructure, not a one-off. The official Scrapy documentation is excellent and the community is large, so you won't be stranded.
When should you use Apify over Scrapy?#
Reach for Apify when:
- You need data this week, not after a two-sprint build.
- Targets are JavaScript-heavy or behind serious bot detection.
- You don't want to run servers, proxies, or schedulers.
- A pre-built Store Actor already covers your target site.
- Non-engineers on the team need to trigger or configure runs.

The platform's whole value proposition is removing the boring, brittle 80% of a scraping project so you focus on the data. If that 80% isn't where you want to spend engineering cycles, Apify is the rational choice.
Apify vs Scrapy for B2B lead data: the missing third option#
Here's the trap both tools share: scraping is the easy part of building a B2B dataset. The hard part is what comes after.
Say you scrape company websites for contact pages. You'll get inconsistent formats, missing fields, role pages without emails, and a lot of info@ catch-alls that bounce. Now you need to find the right person's email, verify it's deliverable, and enrich it with title, company size, and phone. That's a second project bigger than the scraper.
| Approach | Time to usable leads | Maintenance | Data quality |
|---|---|---|---|
| Scrapy from scratch | Weeks | High | You build verification yourself |
| Apify Store Actor | Days | Medium | Depends on Actor + your cleanup |
| Purpose-built data API | Minutes | None | Verified emails + enrichment included |
If your actual goal is outreach-ready contacts, scraping raw pages is the long way around. A dedicated provider hands you verified data through one call. Tomba's email finder API returns professional emails by domain or name, the data enrichment endpoint fills in firmographics, and bulk lead generation processes whole lists at once — no proxies, no selectors, no 3 a.m. selector breakage.
You can still use Scrapy or Apify to discover which companies and people to target, then hand the domains to a B2B database that already knows the email patterns. That hybrid — scrape for discovery, API for contact data — is what most efficient teams actually run.

Can you run Scrapy on Apify?#
Yes, and it's a genuinely good middle path. Apify supports running Scrapy spiders as Actors, so you keep your Python code and selectors while inheriting Apify's proxies, scheduling, storage, and scaling. You get Scrapy's control over parsing and Apify's operational backbone in one place.
This is worth knowing because the choice isn't always either/or. A team with existing Scrapy spiders that's drowning in proxy and infra maintenance can lift those spiders onto Apify without a rewrite — keeping the parsing logic they trust while offloading the ops they hate.
Final verdict: which should you choose in 2026?#
Choose Scrapy if scraping is core infrastructure, you have Python talent, your targets are stable, and high volume makes unit cost king. Choose Apify if you value speed, your targets fight bots, and you'd rather pay a predictable bill than staff an ops team. And if you can run Scrapy on Apify, you don't have to pick a side at all.
But step back before you build anything. If the dataset you actually need is verified B2B contacts, the fastest, most reliable path skips the scraper entirely. Start with the Tomba Email Finder — give it a domain or a name and company, and get back a verified professional email in seconds, with enrichment and bulk processing ready when you scale. Let the scraping frameworks do discovery, and let a purpose-built tool deliver the contacts that turn into pipeline.
Ready to find emails that actually work?
Join 150,000+ professionals who stopped guessing and started sending. Free credits on signup — no credit card required.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author