How to Automate Deal Reviews in 2026: A Practical Guide
Manual deal reviews eat hours and still miss slipping deals. Here's how to automate deal reviews in 2026 with clean CRM data, scoring rules, and AI summaries.

TL;DR
- Automating deal reviews means letting your CRM, scoring rules, and AI summaries do the prep work so reps and managers spend the meeting deciding, not reporting.
- The four pillars are clean data, a shared deal-health score, automated risk flags, and a templated review cadence.
- Bad contact data quietly breaks deal reviews: stale buyers, wrong stakeholders, and missing contacts make forecasts lie.
- A practical stack pairs your CRM with enrichment, scoring automation, and an AI summarizer — no rip-and-replace required.
- Start with one segment, prove the time savings, then roll the automation out across the team.
Deal reviews are where pipeline goes to be honest — or where it goes to hide. Done well, they catch slipping deals weeks before they slip. Done the usual way, they're a manager reading a spreadsheet aloud while reps narrate from memory. This guide shows you how to automate deal reviews so the boring 80% runs itself and your team spends the meeting on judgment calls that actually move revenue.
What does it mean to automate deal reviews?#
To automate deal reviews is to remove the manual prep, data-gathering, and status-narration from your pipeline meetings so the system surfaces what needs attention before anyone joins the call. Think of it like a pre-flight checklist: instead of the pilot inspecting every rivet by hand, sensors report what's off and the crew focuses on decisions. The review still happens — humans still decide — but the data assembly, risk scoring, and summary writing are handled by software.
A fully manual deal review usually looks like this: a manager exports the pipeline, pings five reps for updates, copies notes into a deck, and runs a 60-minute meeting where half the time is spent reconciling what's actually true. An automated review flips that. By the time the meeting starts, every deal already has a health score, a last-activity timestamp, a stakeholder map, and a one-paragraph AI summary of what changed since last week.
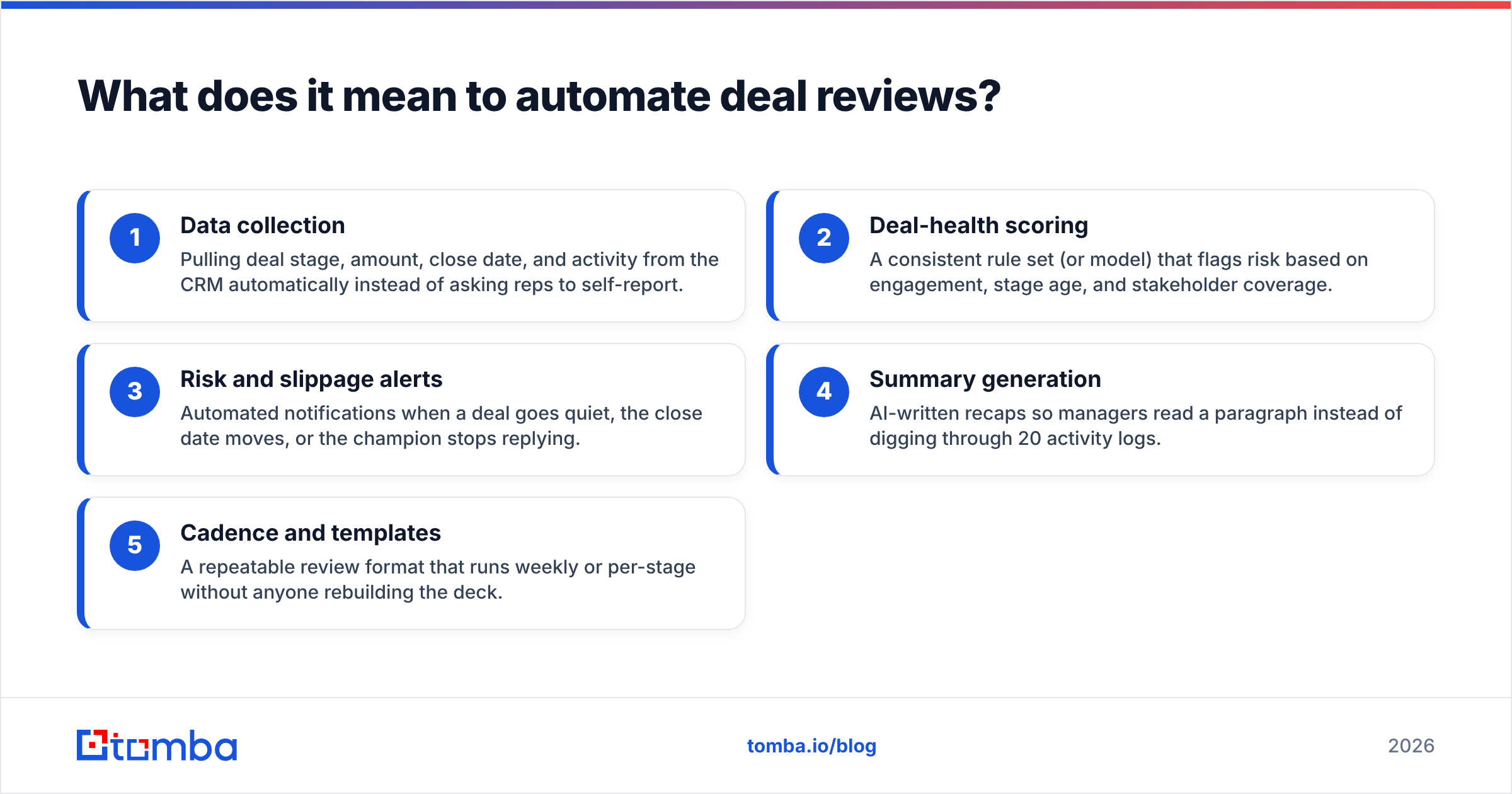
Here are the core building blocks you're automating:
- Data collection — Pulling deal stage, amount, close date, and activity from the CRM automatically instead of asking reps to self-report.
- Deal-health scoring — A consistent rule set (or model) that flags risk based on engagement, stage age, and stakeholder coverage.
- Risk and slippage alerts — Automated notifications when a deal goes quiet, the close date moves, or the champion stops replying.
- Summary generation — AI-written recaps so managers read a paragraph instead of digging through 20 activity logs.
- Cadence and templates — A repeatable review format that runs weekly or per-stage without anyone rebuilding the deck.
)
Notice what isn't on that list: judgment. Automation does not decide whether to discount, escalate, or walk away. It clears the runway so humans can.
Why do manual deal reviews fail?#
Manual deal reviews fail because they depend on human memory, self-reported data, and time nobody has. Three failure modes show up again and again.
They rely on stale or self-reported data. When a rep says "this one's looking good," that's a feeling, not a signal. According to research summarized by Gartner, buyers now spend the majority of their journey doing independent research, which means your CRM activity log often tells a truer story than the rep's gut. If that log is incomplete, the review is built on sand.
They eat senior time. A weekly review across five reps and 40 deals can consume four to six hours of manager prep plus the meeting itself. That's time a frontline manager should spend coaching, not formatting slides.
They surface problems too late. The whole point of a review is early warning. But a deal that's been silent for three weeks usually doesn't get flagged until the manager happens to notice — by which point the buyer has gone cold. Automated slippage alerts close that gap.
There's a quieter failure mode too: bad contact data. If the champion changed jobs, the economic buyer was never added, or the only email on the account bounces, your deal review is reviewing a fiction. This is where contact accuracy quietly determines forecast accuracy. Keeping stakeholder records current with data enrichment and verified contacts is unglamorous, but it's the foundation everything else sits on.
What does an automated deal review stack look like?#
An automated deal review stack has four layers: a system of record, a data-quality layer, a scoring/alerting engine, and a summarization layer. You almost certainly own the first one already. The table below maps each layer to its job and example tooling.
| Layer | Job in the review | Example tools | Automation payoff |
|---|---|---|---|
| System of record (CRM) | Stores stage, amount, close date, activity | HubSpot, Salesforce, Pipedrive | Single source of truth for every deal |
| Data quality / enrichment | Keeps contacts, stakeholders, and emails current | Tomba enrichment, verified emails | Stops reviews built on dead contacts |
| Scoring & alerting | Flags risk, slippage, and silent deals | CRM workflows, scoring apps | Risk surfaces before the meeting |
| Summarization | Writes the "what changed" recap | AI summarizers, Gong-style tools | Managers read a paragraph, not 20 logs |
You don't buy all four at once. Most teams already have a CRM and bolt on the other three incrementally. The biggest early win is usually the data-quality layer, because it makes every layer above it more trustworthy.
How do you score deal health automatically?#
Score deal health by combining a handful of objective signals into one number or color. A simple, transparent rule set beats a black-box model when you're starting out, because reps trust what they can see. A workable starter scorecard:
- Engagement recency — Days since last meaningful buyer activity (reply, meeting, doc view). Over 14 days quiet drops the score.
- Stage age — Days in current stage vs. your historical average. A deal stuck 2x longer than normal is a flag.
- Stakeholder coverage — Are economic buyer, champion, and technical evaluator all identified and reachable? Missing roles lower the score.
- Close-date integrity — How many times has the close date been pushed? Each slip compounds risk.
- Next-step defined — Is there a scheduled, mutual next step? No next step is the single most reliable warning sign.
Each signal is cheap to compute from CRM fields you already capture. The magic isn't sophistication; it's consistency. Every deal scored the same way, every week, with no rep spin.
)

How do you actually set this up step by step?#
Set it up in five stages, each shippable on its own so you see value before finishing the whole thing.
Step 1 — Standardize your pipeline stages and exit criteria. Automation can't score what isn't defined. Write down what "qualified," "proposal," and "negotiation" actually require. If two reps disagree on what a stage means, fix that before automating anything.
Step 2 — Clean and enrich your contact data. Run your open-pipeline accounts through verification and enrichment so every active deal has a current champion, a reachable email, and the key stakeholders mapped. A bounced champion email is a silent deal-killer. Tools like the Tomba Email Finder and domain search help you fill stakeholder gaps when a deal only has one contact on it.
Step 3 — Build your scoring rules in the CRM. Translate the scorecard above into CRM workflow rules or a scoring app. Start with three signals, not ten. You can always add nuance once the team trusts the basics.
Step 4 — Wire up alerts. Push slippage and silent-deal flags to where reps already live — Slack, email, or the CRM dashboard. An alert nobody sees is not an alert. Many teams route these through Zapier or native HubSpot and Salesforce integrations.
Step 5 — Template the meeting. Replace the freeform review with a fixed agenda driven by the score: review only red and amber deals, confirm next steps, assign actions. Green deals get a glance, not a recitation. This alone can cut review time in half.
Run all five against a single team or segment first. Prove the hours saved, capture a before/after, then expand.
Build vs. buy: how much should you automate yourself?#
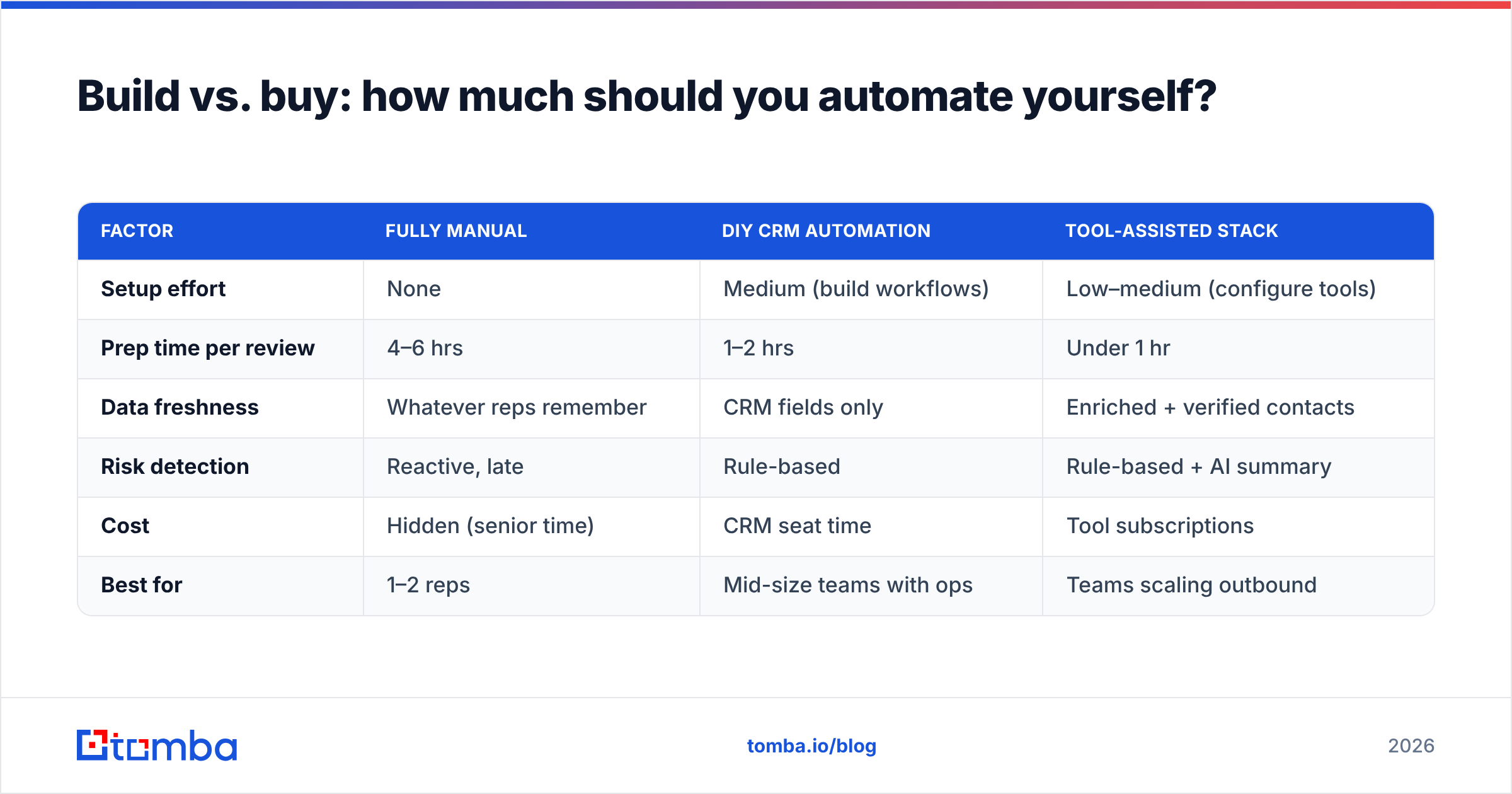
The honest answer is hybrid — automate the data and scoring with tools, keep the judgment human. The comparison below frames the trade-off across three common approaches so you can pick the one that fits your stage and budget.
| Factor | Fully manual | DIY CRM automation | Tool-assisted stack |
|---|---|---|---|
| Setup effort | None | Medium (build workflows) | Low–medium (configure tools) |
| Prep time per review | 4–6 hrs | 1–2 hrs | Under 1 hr |
| Data freshness | Whatever reps remember | CRM fields only | Enriched + verified contacts |
| Risk detection | Reactive, late | Rule-based | Rule-based + AI summary |
| Cost | Hidden (senior time) | CRM seat time | Tool subscriptions |
| Best for | 1–2 reps | Mid-size teams with ops | Teams scaling outbound |
Most growing teams land in the third column. The DIY route works if you have a dedicated revenue operations function to maintain it; without one, native workflows rot fast. The tool-assisted path trades a subscription for reliability and keeps your ops people focused on strategy instead of plumbing.
If you want a sanity check on vendor categories before buying, peer-review sites like G2 are useful for seeing how scoring, forecasting, and enrichment tools are rated by actual users rather than by their own marketing.
What does automation get wrong (and how do you avoid it)?#
Automation fails in predictable ways, and knowing them upfront saves you a painful quarter.
Garbage in, garbage out. If your CRM data is dirty, an automated score just makes wrong conclusions faster and with more confidence. This is why the data-quality layer comes first. Verify contacts, dedupe records, and keep stakeholder maps current. A B2B database refresh on your active accounts each quarter is cheap insurance.
Over-trusting the score. A health score is a conversation starter, not a verdict. A "red" deal might be red because the buyer is on vacation, not because it's dead. The meeting is where humans add the context the score can't see.
Alert fatigue. Fire too many flags and reps tune them all out. Tune thresholds so alerts stay rare and meaningful. One sharp flag beats ten soft ones.
Forgetting the human cadence. Automation handles prep, but coaching is still a conversation. Don't let the dashboard replace the manager. The best teams use the freed-up time to coach harder, not to meet less.
How do you measure whether it worked?#
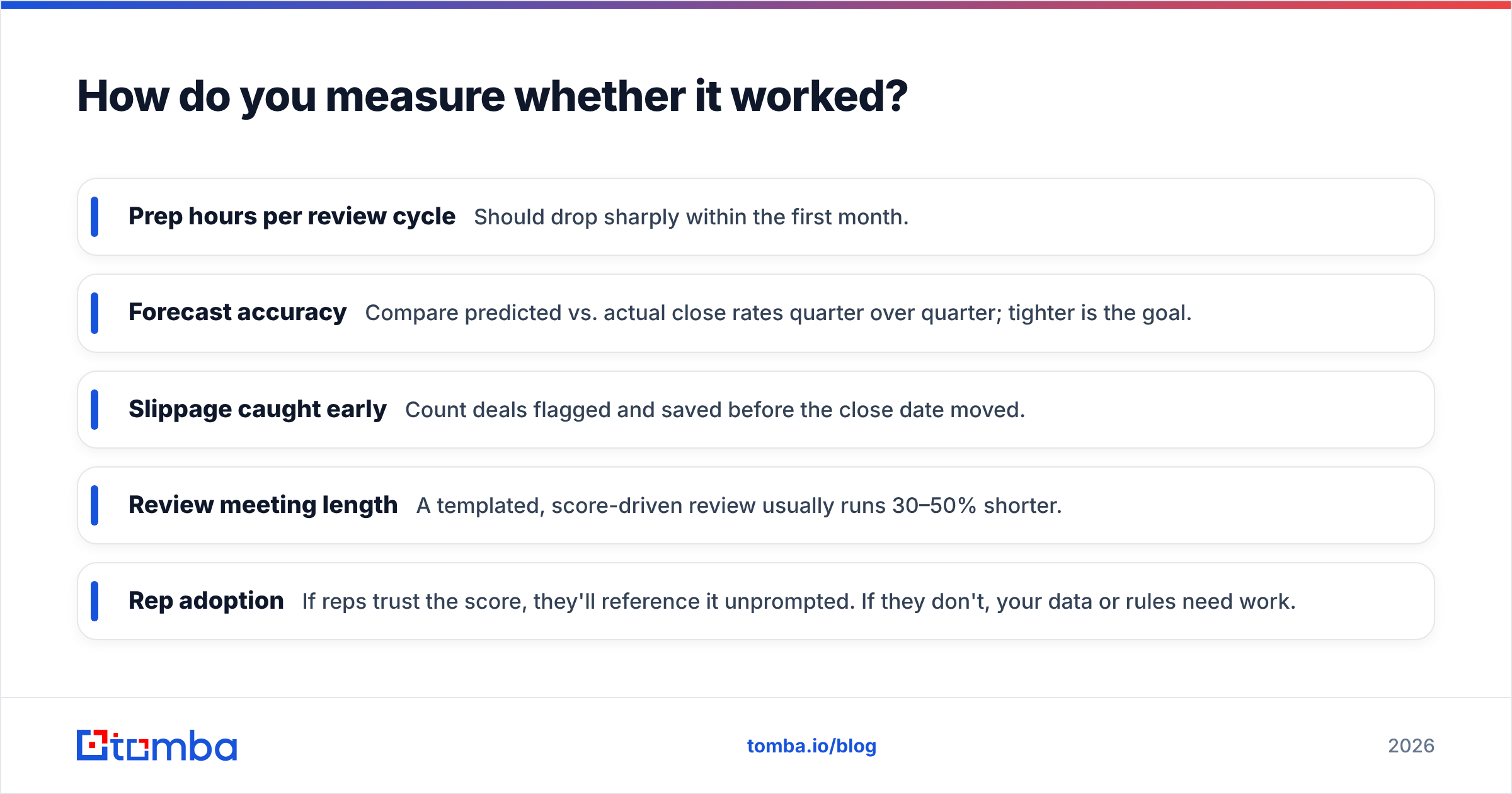
Measure automation by time reclaimed and forecast accuracy, not by how impressive the dashboard looks. Track these before-and-after:
- Prep hours per review cycle — Should drop sharply within the first month.
- Forecast accuracy — Compare predicted vs. actual close rates quarter over quarter; tighter is the goal.
- Slippage caught early — Count deals flagged and saved before the close date moved.
- Review meeting length — A templated, score-driven review usually runs 30–50% shorter.
- Rep adoption — If reps trust the score, they'll reference it unprompted. If they don't, your data or rules need work.
If those numbers move the right way against your win rate and cycle time, the automation is earning its keep. If they don't, the problem is almost always upstream — usually data quality or fuzzy stage definitions — not the automation itself.
Final take: where to start tomorrow#
You don't need a six-month transformation project to automate deal reviews. You need clean data, three scoring rules, one alert, and a templated agenda — applied to a single team. The compounding win is real: every hour your managers stop spending on prep is an hour they spend coaching, and every silent deal caught early is revenue that would otherwise have quietly vanished.
The layer most teams underestimate is contact accuracy, because it's invisible until it isn't. A deal review built on a champion who left three months ago is just confident guessing. Start by making sure every active deal has verified, enriched, reachable stakeholders — then let scoring and AI handle the rest.
Ready to fix the data layer first? Use the Tomba Email Finder to fill stakeholder gaps on your open pipeline, verify the contacts you already have, and keep every deal review grounded in people who actually still work there. Check Tomba pricing — the free tier covers 25 searches a month so you can test it against your live deals before committing. Clean contacts in, trustworthy reviews out.
Ready to find emails that actually work?
Join 150,000+ professionals who stopped guessing and started sending. Free credits on signup — no credit card required.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author