What Is a B2B Identity Graph? The 2026 Data Guide
A B2B identity graph stitches scattered signals into one trusted record per person and account. Here's how it works, where the data comes from, and how to build one in 2026.

TL;DR
- A B2B identity graph is a connected map that links every signal you collect — emails, domains, LinkedIn profiles, phone numbers, web visits — to one canonical record per person and per company.
- It exists to solve one problem: your data is scattered across tools, half of it is stale, and you can't tell whether "j.smith@acme.com" and "John Smith, Acme Corp" are the same human.
- The core engine is identity resolution — matching, merging, and de-duplicating records using deterministic keys (email, domain) and probabilistic signals (name + company + title).
- You don't have to build the whole thing. Enrichment and verification APIs supply the connective tissue (verified emails, firmographics, social handles) that a graph needs to stay accurate.
- Accuracy decays fast — roughly 25–30% of B2B contact data goes stale every year — so a graph is only as good as its refresh and verification loop.
What is a B2B identity graph?#
A B2B identity graph is a single source of truth that connects fragmented identifiers — work emails, personal emails, phone numbers, LinkedIn URLs, company domains, and behavioral events — into unified profiles for people and the accounts they belong to.
Think of it like a hotel front desk. A guest might book under a nickname, pay with a corporate card, order room service from a different name, and check out under a third spelling. The front desk's job is to recognize that all of those touchpoints are one guest in room 412. An identity graph does the same thing for your go-to-market data: it recognizes that the form-fill from "jsmith@gmail.com," the LinkedIn visit from "John Smith," and the CRM lead "J. Smith @ Acme" are the same buyer at the same account.
Technically, the graph is a network of nodes (entities like a person or company) and edges (the verified relationships between them — "works at," "same email," "same device"). Every node carries attributes: title, seniority, location, firmographics. Every edge carries a confidence score. The graph's value is not the raw data — it's the resolved connections.

Why does a B2B identity graph matter in 2026?#
Because the cost of not having one shows up everywhere: duplicate records inflate your CRM, reps email the wrong person, attribution breaks, and ABM campaigns target accounts you already closed. Gartner has long pegged poor data quality as a multi-million-dollar annual drag on the average enterprise, and the math is simple — every wrong field multiplies across every downstream play.
Three forces make this sharper in 2026:
- Signal sprawl. Buyers leave traces across LinkedIn, your website, review sites like G2, webinars, and intent providers. Without a graph, each tool holds a partial, contradictory view.
- Privacy-driven fragmentation. Cookie deprecation and stricter consent rules mean you can no longer rely on third-party tracking to stitch sessions. First-party, declared identifiers (verified work email, domain) are now the durable spine.
- AI-driven outbound at scale. AI SDRs and automated sequences amplify whatever data you feed them. Feed them a clean graph and they personalize well; feed them duplicates and stale rows and they burn your domain reputation faster than any human could.
The identity graph is the layer that turns "a pile of leads" into "a queryable model of your market."
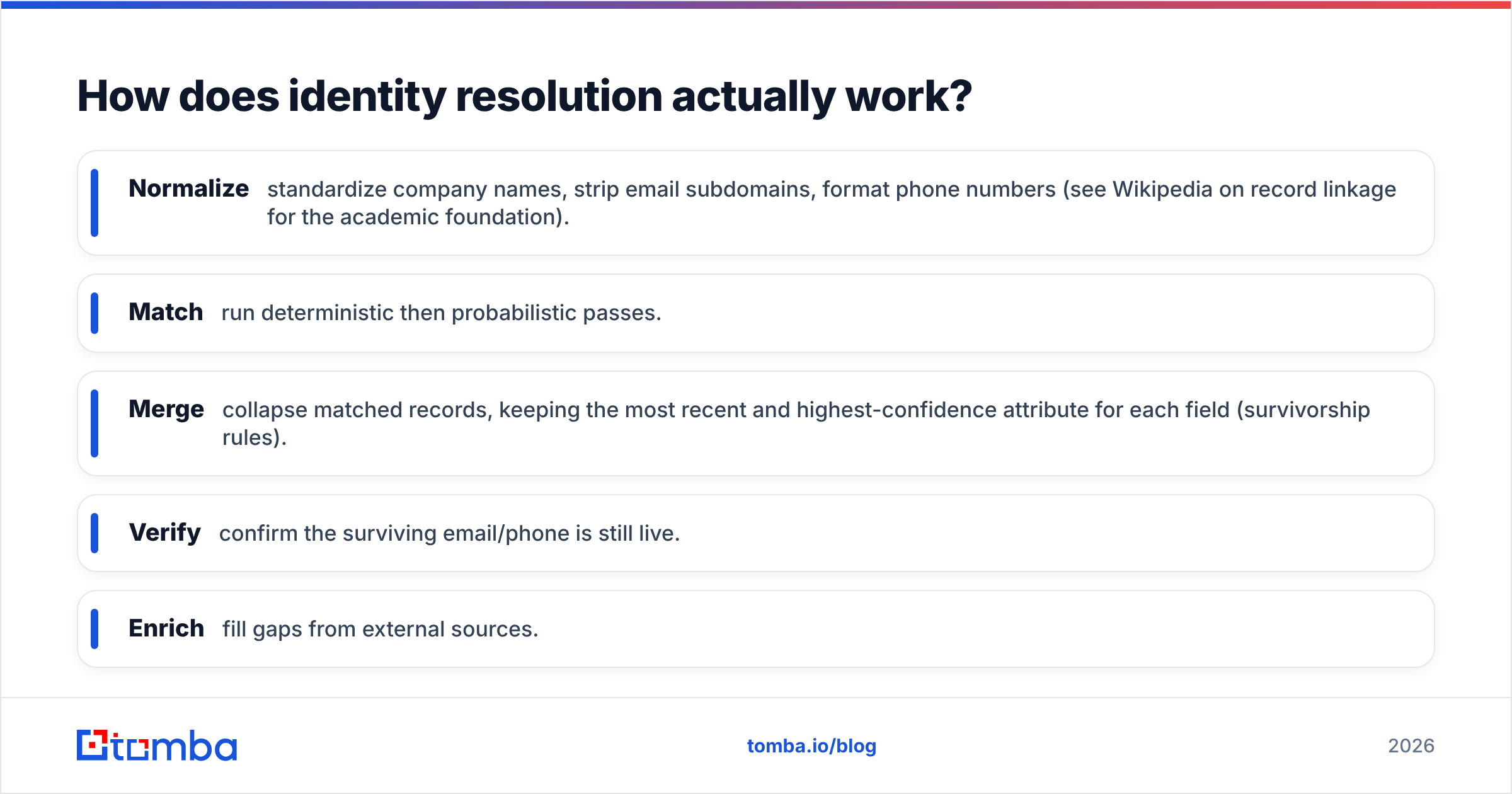
How does identity resolution actually work?#
Identity resolution is the matching process underneath the graph. It runs in three passes, from most to least certain:
- Deterministic matching — exact matches on unique keys. Same verified email or same company domain = same node, full stop. This is your highest-confidence, lowest-risk layer.
- Probabilistic matching — fuzzy logic on combinations: name + employer + title, or normalized company name + location. "Bob Smith, VP Sales, Acme" and "Robert Smith, Sales VP, Acme Corp" resolve to one person with high probability.
- Heuristic / referential matching — using a known reference dataset (a B2B database) to confirm that a guessed connection is real, e.g., validating that an email pattern actually exists at a domain before merging.
The output of each match is a confidence score. Above a threshold you merge; in a gray zone you flag for review; below it you keep records separate. Getting these thresholds right is the difference between a clean graph and one that silently fuses two different people named John Smith.
A practical resolution stack looks like this:
- Normalize — standardize company names, strip email subdomains, format phone numbers (see Wikipedia on record linkage for the academic foundation).
- Match — run deterministic then probabilistic passes.
- Merge — collapse matched records, keeping the most recent and highest-confidence attribute for each field (survivorship rules).
- Verify — confirm the surviving email/phone is still live.
- Enrich — fill gaps from external sources.
What data sources feed a B2B identity graph?#
A graph is only as strong as the signals flowing into it. The sources fall into a few buckets, each with different freshness and trust profiles. You can pull most of these together with contact enrichment and a solid reverse email lookup to connect an unknown email back to a person.
| Source type | Examples | What it provides | Freshness risk |
|---|---|---|---|
| First-party | Forms, CRM, product usage | Declared email, intent, ownership | Low (but decays) |
| Firmographic | Domain search, company registries | Industry, size, revenue, domain | Medium |
| Contact data | Email finder, phone finder | Verified work email, direct dials | High — needs constant re-verification |
| Social / professional | LinkedIn profiles, public bios | Title, seniority, job changes | High |
| Behavioral | Web visits, intent providers | Engagement, buying signals | Very high (real-time) |
The trap is treating all sources as equal. A verified work email is a strong deterministic key; a scraped social handle is a weak probabilistic hint. Your graph should weight them accordingly and re-verify the high-decay sources on a schedule.


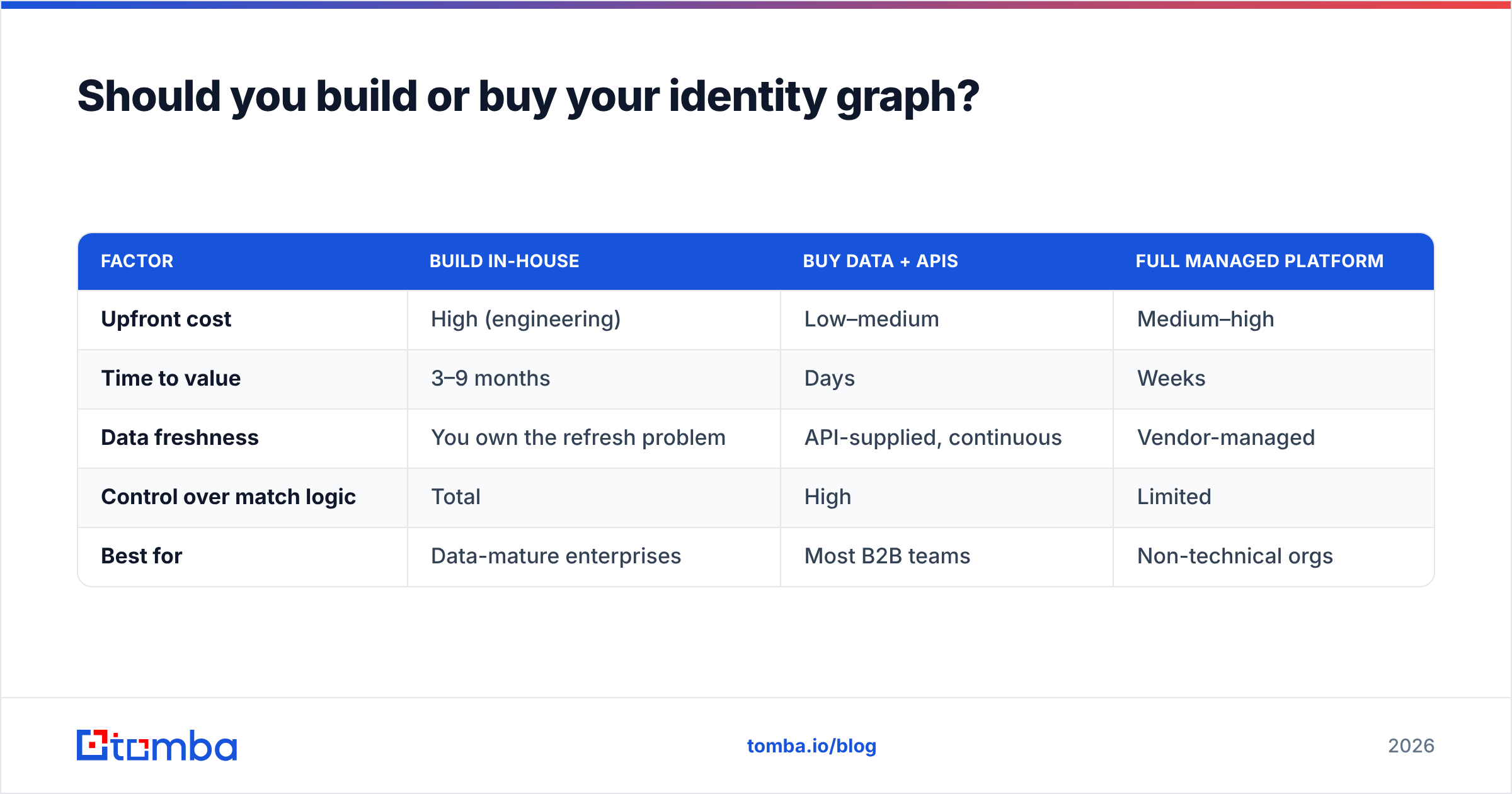
Should you build or buy your identity graph?#
Most teams should buy the data layer and build the resolution logic — full DIY only pays off at enterprise scale with a dedicated data engineering team.
Here's the honest trade-off:
| Factor | Build in-house | Buy data + APIs | Full managed platform |
|---|---|---|---|
| Upfront cost | High (engineering) | Low–medium | Medium–high |
| Time to value | 3–9 months | Days | Weeks |
| Data freshness | You own the refresh problem | API-supplied, continuous | Vendor-managed |
| Control over match logic | Total | High | Limited |
| Best for | Data-mature enterprises | Most B2B teams | Non-technical orgs |
The middle column is where most companies land. You keep control of how records merge (your survivorship and threshold rules are business logic), while outsourcing the expensive, never-finished work of sourcing and verifying contact data. Pull verified emails and firmographics through an API, store the resolved graph in your own warehouse, and you get the best of both.
If you go this route, budget realistically. A credit-based pricing model — for example, Tomba's Free tier (25 searches/mo), Starter at $49/mo, Growth at $99/mo, and Pro at $249/mo — lets you map cost directly to graph volume instead of signing a six-figure platform contract before you've proven the model.
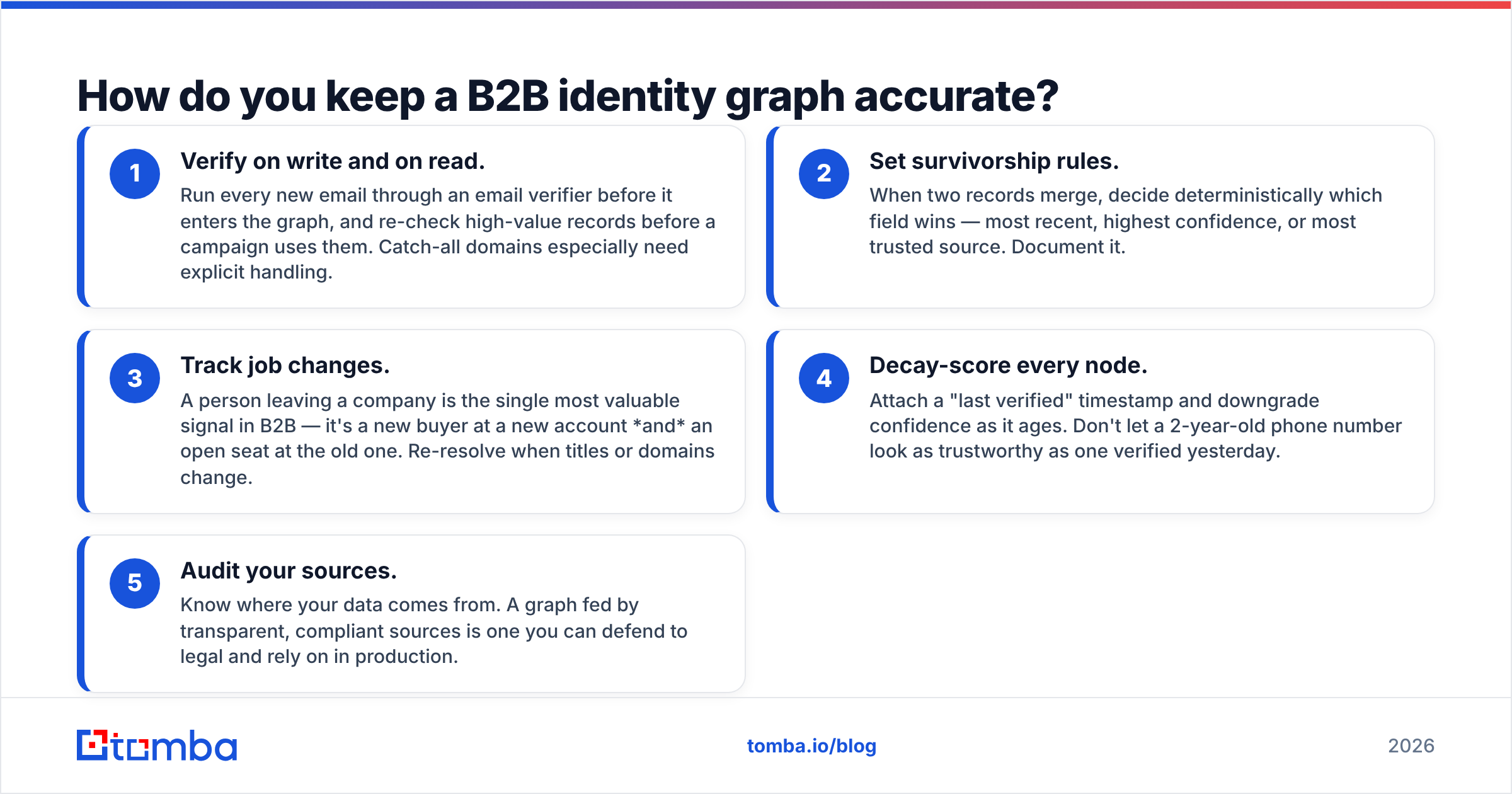
How do you keep a B2B identity graph accurate?#
Accuracy is a maintenance problem, not a one-time build. Roughly a quarter to a third of B2B contact records rot every year as people change jobs, companies rebrand, and domains migrate. A graph that isn't actively refreshed becomes a confident liar.
Five practices keep it honest:
- Verify on write and on read. Run every new email through an email verifier before it enters the graph, and re-check high-value records before a campaign uses them. Catch-all domains especially need explicit handling.
- Set survivorship rules. When two records merge, decide deterministically which field wins — most recent, highest confidence, or most trusted source. Document it.
- Track job changes. A person leaving a company is the single most valuable signal in B2B — it's a new buyer at a new account and an open seat at the old one. Re-resolve when titles or domains change.
- Decay-score every node. Attach a "last verified" timestamp and downgrade confidence as it ages. Don't let a 2-year-old phone number look as trustworthy as one verified yesterday.
- Audit your sources. Know where your data comes from. A graph fed by transparent, compliant sources is one you can defend to legal and rely on in production.
The teams that win treat the graph as a living system with an SLA on freshness — not a spreadsheet they refresh once a quarter.
What does a B2B identity graph unlock once it works?#
A working graph stops being a data project and starts being a revenue engine. With one resolved record per person and account, you can:
- De-duplicate the CRM so reps stop stepping on each other and forecasting stops double-counting.
- Route leads correctly the instant a form is filled, because you already know which account and territory that email belongs to.
- Power ABM with account-level rollups — every contact, signal, and touch tied to the parent company.
- Feed AI outbound clean inputs, so automated personalization references real, current titles instead of hallucinated ones.
- Measure attribution across the full journey, because every touchpoint resolves to the same canonical buyer.
None of this requires a moonshot. It requires a spine of verified identifiers and disciplined resolution logic on top.
Getting started without overbuilding#
Start narrow. Pick one high-value use case — say, de-duplicating inbound leads against your existing accounts — and build the smallest graph that solves it. Resolve on verified work email as your deterministic key, enrich the gaps, verify before merge, and only then expand to behavioral signals and probabilistic matching.
The fastest way to seed that spine is with accurate, verified contact data at the entry point. Tomba's Email Finder turns a name and company domain into a verified professional email — the exact deterministic key an identity graph is built around — and pairs with domain search, enrichment, and verification so the records you resolve are real before they ever reach your graph. Start on the free tier, prove the resolution model on a single workflow, and scale the credits as your graph grows. That's how you build a B2B identity graph that compounds in value instead of decaying in a spreadsheet.
Ready to find emails that actually work?
Join 150,000+ professionals who stopped guessing and started sending. Free credits on signup — no credit card required.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author