B2B Identity Resolution in 2026: The Complete Guide
B2B identity resolution stitches fragmented signals into one trusted account-and-contact record. Here's how it works, what to buy, and how to fix match accuracy in 2026.

B2B Identity Resolution in 2026: The Complete Guide
TL;DR
- B2B identity resolution is the process of merging scattered signals — form fills, website visits, CRM rows, enrichment records — into a single trusted profile for each person and each account.
- Two engines do the work: deterministic matching (exact keys like email or domain) and probabilistic matching (weighted similarity across name, company, and behavior).
- The hard part is not the algorithm; it's the input data. Garbage emails and stale firmographics cap your match rate no matter how good the model is.
- Most teams stitch identity with a layered stack: a CRM of record, an enrichment/verification layer, and a reverse-lookup or visitor-reveal source on top.
- You can lift match rates 15–30% just by verifying contact data and standardizing company identifiers before resolution runs.
What is B2B identity resolution?#
B2B identity resolution is the discipline of deciding that "Jane Doe, VP Marketing" in your webinar list, "j.doe@acme.io" in your CRM, and an anonymous visitor from acme.io are all the same person at the same account — and then collapsing them into one record.
Think of it like a hotel front desk during a conference. Three hundred guests check in under slightly different names — "Bob Smith," "Robert Smith," "R. Smith from Acme" — and the clerk's job is to match each one to the right reservation without handing out the wrong room key. Identity resolution is that clerk, running at scale across millions of noisy rows.
Technically, it sits at the center of B2B data and intelligence: it links a person identity (the contact) to an account identity (the company), and keeps both updated as people switch jobs and companies get acquired. Without it, your funnel double-counts leads, your routing sends two reps to the same buyer, and your attribution lies to you.

Why does B2B identity resolution matter now?#
Three forces made this a 2026 priority instead of a nice-to-have.
- Signal explosion. The average buying committee now touches 10+ channels before a sales conversation. Each channel emits a different identifier, and none of them agree out of the box.
- Privacy-driven anonymity. Cookie deprecation and stricter consent rules mean more of your traffic is anonymous. Resolving who that traffic belongs to — at the account level — is now a competitive edge, not a back-office task.
- AI-driven outreach. Every AI SDR and sales automation tool is only as good as the identity graph underneath it. Feed it duplicates and it sends three "personalized" emails to the same person.
The cost of getting it wrong is concrete. Gartner has long estimated that poor data quality costs organizations millions annually in wasted effort and bad decisions, and identity is the layer where that cost compounds fastest. Bad identity resolution doesn't just lose a record — it pollutes every downstream system that trusts it.
How does B2B identity resolution actually work?#
The pipeline is consistent across vendors, even when the marketing language is not. Here are the five stages every serious system runs:
- Ingestion — pull records from every source: CRM, MAP, product analytics, enrichment feeds, ad platforms, and website visitor reveal.
- Normalization — standardize the messy fields. "Acme, Inc.", "ACME Incorporated", and "acme.io" must resolve to one canonical company key (usually the root domain).
- Matching — apply deterministic and probabilistic logic to cluster records that belong together.
- Merging / survivorship — when two records match, decide which field value wins (newest? most trusted source? verified?). This "golden record" logic is where most teams quietly lose accuracy.
- Activation — push the resolved identity back to the CRM, ad platforms, and outreach tools so the rest of the stack benefits.
The matching stage gets the headlines, but normalization and survivorship decide your real-world quality. A perfect matcher fed inconsistent company names will still split one account into five.
Deterministic vs probabilistic matching#
These are the two engines, and most production systems blend them.
| Attribute | Deterministic matching | Probabilistic matching |
|---|---|---|
| Core logic | Exact match on a unique key (email, domain, LinkedIn URL) | Weighted similarity across many fuzzy attributes |
| Accuracy when keys exist | Very high (near 100%) | High but tunable |
| Coverage on messy data | Low — misses typos and missing keys | High — tolerates partial data |
| False-positive risk | Very low | Moderate; needs threshold tuning |
| Best for | Verified emails, validated domains | Anonymous traffic, sparse records |
| Maintenance cost | Low | Higher (model + threshold upkeep) |
The practical rule: use deterministic matching wherever you have a clean key, and fall back to probabilistic matching only for the records that lack one. That ordering keeps your false-positive rate low while still catching the long tail. And the single highest-leverage thing you can do for the deterministic layer is to feed it verified identifiers — which is exactly where contact data quality enters the picture.

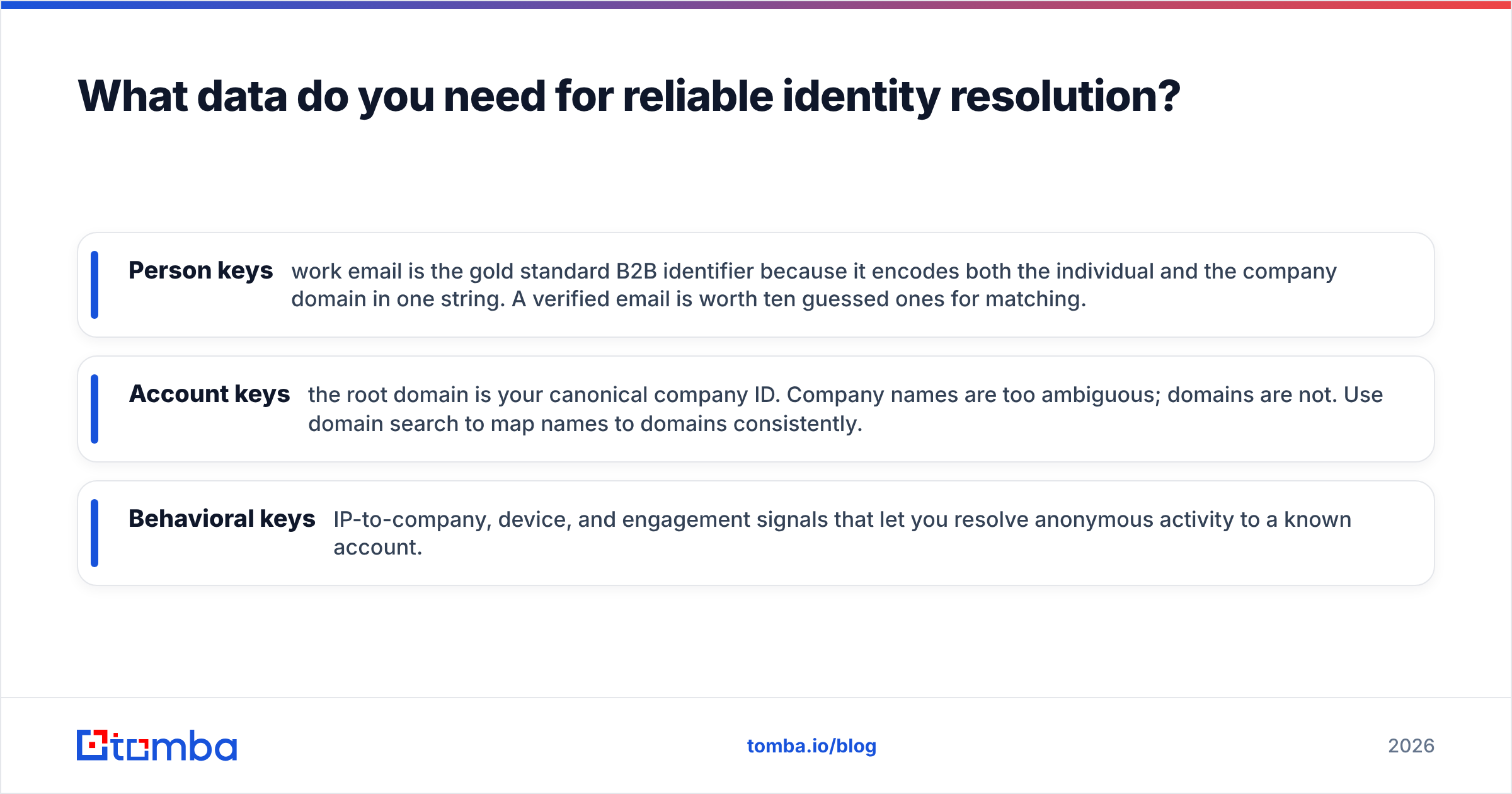
What data do you need for reliable identity resolution?#
You need three identifier classes, and a verification step on top of each.
- Person keys — work email is the gold standard B2B identifier because it encodes both the individual and the company domain in one string. A verified email is worth ten guessed ones for matching.
- Account keys — the root domain is your canonical company ID. Company names are too ambiguous; domains are not. Use domain search to map names to domains consistently.
- Behavioral keys — IP-to-company, device, and engagement signals that let you resolve anonymous activity to a known account.
Here's the part teams skip: verify before you resolve. If 18% of your emails are invalid or catch-all, your deterministic layer silently fails on nearly a fifth of records and dumps them into the noisier probabilistic path. Running an email verifier and a catch-all verifier up front is the cheapest accuracy upgrade available. The cleaner your keys, the less you lean on fuzzy matching — and the fewer false merges you create.

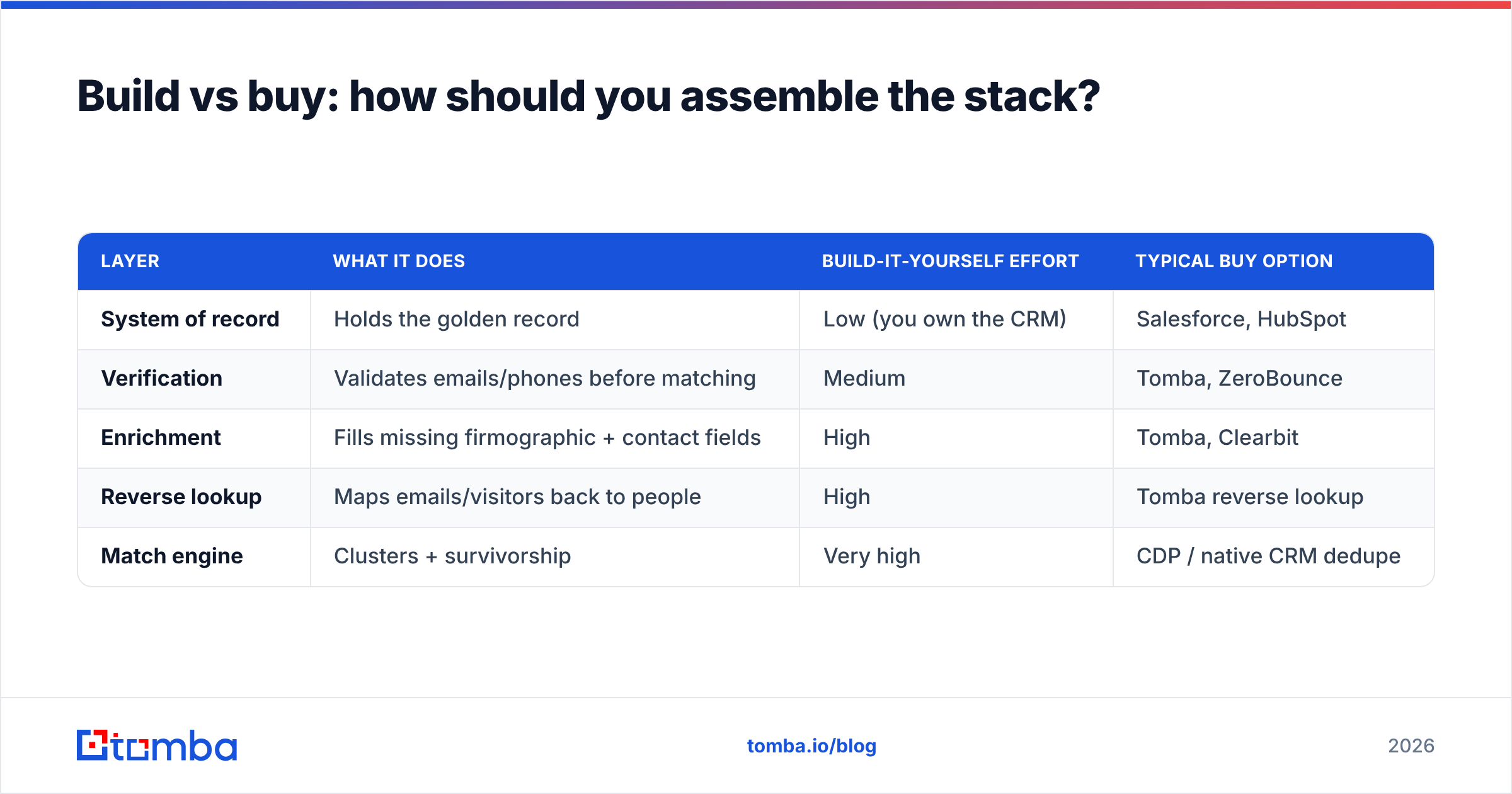
Build vs buy: how should you assemble the stack?#
Almost nobody builds a full identity graph from scratch anymore — the data acquisition cost alone is prohibitive. Instead, you assemble a layered stack and pick where to buy versus configure.
| Layer | What it does | Build-it-yourself effort | Typical buy option |
|---|---|---|---|
| System of record | Holds the golden record | Low (you own the CRM) | Salesforce, HubSpot |
| Verification | Validates emails/phones before matching | Medium | Tomba, ZeroBounce |
| Enrichment | Fills missing firmographic + contact fields | High | Tomba, Clearbit |
| Reverse lookup | Maps emails/visitors back to people | High | Tomba reverse lookup |
| Match engine | Clusters + survivorship | Very high | CDP / native CRM dedupe |
A pragmatic 2026 stack for most mid-market teams looks like this: CRM as the record, an enrichment-plus-verification layer to clean and complete keys, and a reverse email lookup source to resolve sparse or anonymous identities back to a named person. You let the CRM or a CDP handle merge logic, and you feed it clean, verified inputs so the merge actually works.
For teams evaluating dedicated platforms, G2's data quality category is a reasonable starting point for shortlists — but weigh the reviews against your own match-rate tests, not the star ratings. Identity quality is workload-specific; a vendor that nails tech-vertical accounts may underperform on, say, regional manufacturing.
How do you measure identity resolution quality?#
You manage what you measure, so define these four metrics before you buy anything.
- Match rate — share of inbound records successfully linked to an existing person/account. Higher is usually good, but not at the expense of precision.
- Precision (false-merge rate) — how often two different people get merged into one. This is the metric that quietly destroys trust; keep it brutally low.
- Coverage — share of your total addressable accounts you can resolve at all.
- Freshness — how current the resolved attributes are. People change jobs constantly; a 2-year-old title is a liability.
Run a quarterly audit: pull a random sample of 200 merged records and hand-check them. If your false-merge rate creeps above ~1–2%, tighten your probabilistic thresholds or push more records through the deterministic, verified-key path. You can pull fresh, verifiable contacts for that audit set with the Tomba Email Finder and confirm them with the email verifier.
What are the most common identity resolution mistakes?#
- Resolving on unverified data. You're matching on emails that bounce. Verify first; it's the difference between a key and a guess.
- Treating company name as a key. "Apple" vs "Apple Inc" vs "Apple Computer" will fragment one account into three. Always canonicalize to root domain.
- Ignoring survivorship rules. Two matched records, two phone numbers — which wins? If you don't define this, your system picks randomly and your reps call dead lines.
- No re-resolution cadence. Identity is not a one-time job. People switch companies; resolve continuously or your graph rots within a quarter.
- Over-trusting probabilistic matches. Loose thresholds inflate match rate and silently merge strangers. Tune for precision first, then expand coverage.
Notice the pattern: four of the five mistakes trace back to input data quality, not the matching algorithm. That's where the leverage is — and it's also the cheapest layer to fix.
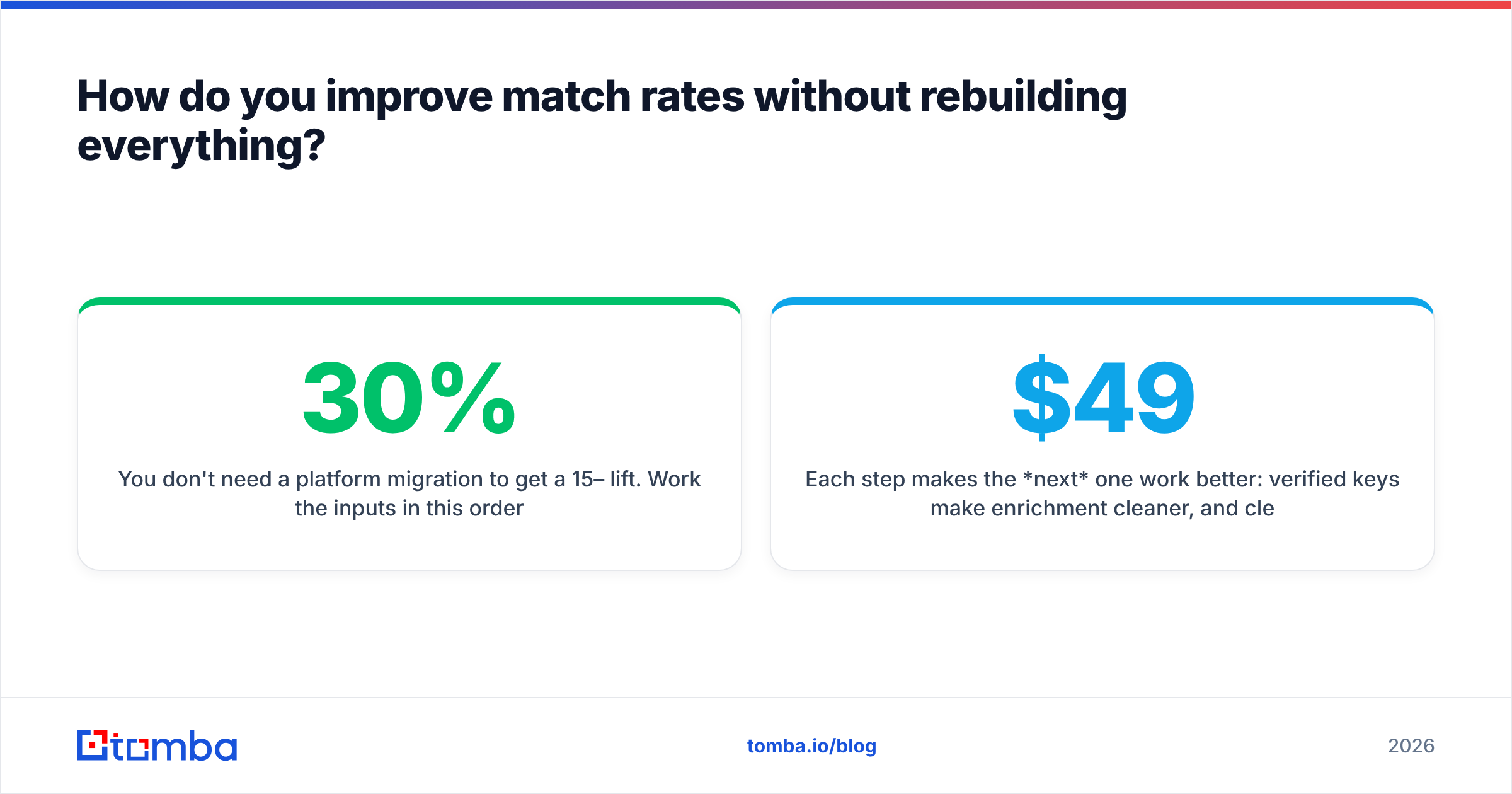
How do you improve match rates without rebuilding everything?#
You don't need a platform migration to get a 15–30% lift. Work the inputs in this order:
- Verify all contact keys. Run your existing database through an email verifier and flag catch-all domains. Invalid keys can't match.
- Canonicalize company identifiers. Map every account to a root domain via domain search so the same company never splits.
- Backfill missing keys. Use a bulk email finder to find the missing work emails that turn fuzzy matches into deterministic ones.
- Enrich the gaps. Apply data enrichment to fill firmographics, then re-run resolution on the completed records.
- Schedule re-resolution. Set a monthly or quarterly job so job-changers and acquisitions don't degrade your graph.
Each step makes the next one work better: verified keys make enrichment cleaner, and clean enrichment makes the match engine's job nearly trivial. This is why the highest-ROI investment in identity resolution is almost never the match engine — it's the verification and finder layer that feeds it. For pricing on those layers, the Tomba pricing page lists a free tier (25 searches/mo), then Starter at $49/mo, Growth at $99/mo, and Pro at $249/mo.
Frequently asked questions#
Is identity resolution the same as data enrichment? No. Enrichment adds attributes to a record; identity resolution decides which records are the same entity and merges them. They're complementary — you typically enrich, then resolve, then re-enrich the golden record.
Can I do B2B identity resolution with just my CRM? Partially. Native CRM dedupe handles obvious deterministic matches, but it lacks the verified keys and reverse-lookup data needed to resolve sparse or anonymous records. Most teams pair the CRM with a verification and finder layer.
How often should I re-run resolution? At minimum quarterly; monthly if you run high-volume outbound. B2B contact data decays roughly 25–30% per year as people change roles, so a static graph degrades fast.
Does identity resolution help with anonymous website traffic? Yes — at the account level. By mapping visitor signals to a company domain through visitor reveal, you can resolve anonymous sessions to known accounts even when you can't identify the individual person.
The bottom line#
B2B identity resolution lives or dies on input quality. The cleverest match engine in the world can't recover from invalid emails and ambiguous company names — but a modest engine fed verified, canonicalized keys will outperform it every time. Fix the inputs first.
If you want to upgrade the data layer that feeds your resolution pipeline, start with the Tomba Email Finder: find verified professional emails by name, company, or domain, confirm them with the built-in verifier, and hand your match engine the clean, deterministic keys it needs to stitch identities correctly. Pair it with bulk processing and enrichment to clean an entire database before your next resolution run — and watch your match rate climb without touching the algorithm.
Ready to find emails that actually work?
Join 150,000+ professionals who stopped guessing and started sending. Free credits on signup — no credit card required.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author