B2B Lead Scoring in 2026: Models, Frameworks & Examples
A practical 2026 guide to B2B lead scoring: fit vs. intent models, point frameworks, common mistakes, and how to feed your model clean, enriched data.

B2B lead scoring is how you stop your sales team from chasing everyone and start them on the few accounts that actually convert. Done right, it turns a noisy inbox of inbound forms and scraped lists into a ranked queue. Done wrong, it's a spreadsheet nobody trusts.
This guide covers the models, a point framework you can copy, real examples, and the data work that quietly decides whether any of it works.
TL;DR#
- B2B lead scoring ranks leads by how likely they are to buy, combining fit (do they match your ICP?) and intent (are they showing buying signals?).
- The three model types are manual point-based, rule-based fit + intent, and predictive (ML) — most teams should start point-based and graduate.
- A workable model usually lives in the 0–100 range with a clear MQL threshold, negative scoring, and decay for stale activity.
- Scores are only as good as the underlying data — missing job titles, wrong company size, and dead emails silently corrupt every model.
- Enrich and verify contact data before scoring with a tool like Tomba Email Finder so fit attributes are complete and reachable.
What is B2B lead scoring?#
B2B lead scoring is the practice of assigning a numeric value to each lead based on how closely they match your ideal customer and how actively they're engaging with your brand. Think of it like a credit score for prospects: instead of guessing who's "hot," you get a number that ranks the whole list.
The score answers one question your reps ask every morning — who do I call first? A lead from a 2,000-employee fintech who visited your pricing page twice this week should outrank a student who downloaded one ebook. Scoring makes that ranking explicit and repeatable instead of leaving it to whoever shouts loudest in the pipeline review.
Two ingredients drive every model:
- Fit (explicit data) — firmographics and demographics: industry, company size, revenue, job title, seniority, geography, tech stack.
- Intent (behavioral data) — what the lead does: email opens, page views, demo requests, content downloads, webinar attendance, repeat visits.
A lead that's high-fit but low-intent is a nurture target. High-intent but low-fit is often a tire-kicker. The sweet spot — high fit and high intent — is where your reps should spend their hours.

Which B2B lead scoring models should you use?#
There are three dominant approaches, and they map to your team's maturity and data volume. You don't pick one forever — you start simple and earn the right to get fancier.
| Model | How it works | Best for | Effort | Pitfall |
|---|---|---|---|---|
| Manual point-based | Assign fixed points per attribute/action | Teams under ~500 leads/mo | Low | Subjective weights |
| Rule-based fit + intent | Two-axis grid (A–D fit × 1–4 intent) | Mid-market with a defined ICP | Medium | Rigid thresholds |
| Predictive (ML) | Model learns from closed-won/lost history | High volume, 1,000+ deals of history | High | Garbage-in, garbage-out |
| Hybrid | Rules for fit, ML for intent ranking | Scaling RevOps teams | High | Tooling complexity |
Most B2B teams overreach here. They buy a predictive scoring add-on before they have enough closed deals to train it, and the model just echoes their existing biases. Start with the point-based model below, run it for a quarter, and only move to predictive once you have a clean, labeled history of wins and losses. For the underlying definitions, the marketing qualified lead and broader lead management concepts are worth aligning your team on first.

How do you build a point-based lead scoring framework?#
Build it in four moves: define the ICP, assign positive points, assign negative points, then set the MQL threshold. Here's a concrete 0–100 framework you can adapt today.
1. Fit attributes (max ~50 points)
- Industry match — target vertical: +15
- Company size — 200–5,000 employees: +15
- Seniority — VP/Director/C-level: +12
- Geography — serviceable region: +8
2. Intent / behavior (max ~50 points)
- Visited pricing page — +15
- Requested a demo — +20
- Opened 3+ emails in 30 days — +8
- Downloaded mid/bottom-funnel content — +7
3. Negative scoring (subtract)
- Personal email domain (gmail, yahoo): −10
- Job title = student/intern: −15
- Unsubscribed or no activity in 60 days: −20 (decay)
- Competitor domain: −25
4. Set the threshold — A lead crossing 70 points becomes an MQL and routes to sales. Below 40 stays in nurture. The 40–70 band is your "watch list."
The negative scoring step is where most models earn their keep. Without it, a high-intent lead with a free Gmail address and a "consultant" title scores the same as a real buyer. Subtracting points for poor fit keeps your reps off the rocks. Decay matters too — a demo request from four months ago is not the same signal as one from yesterday, so let scores fade.
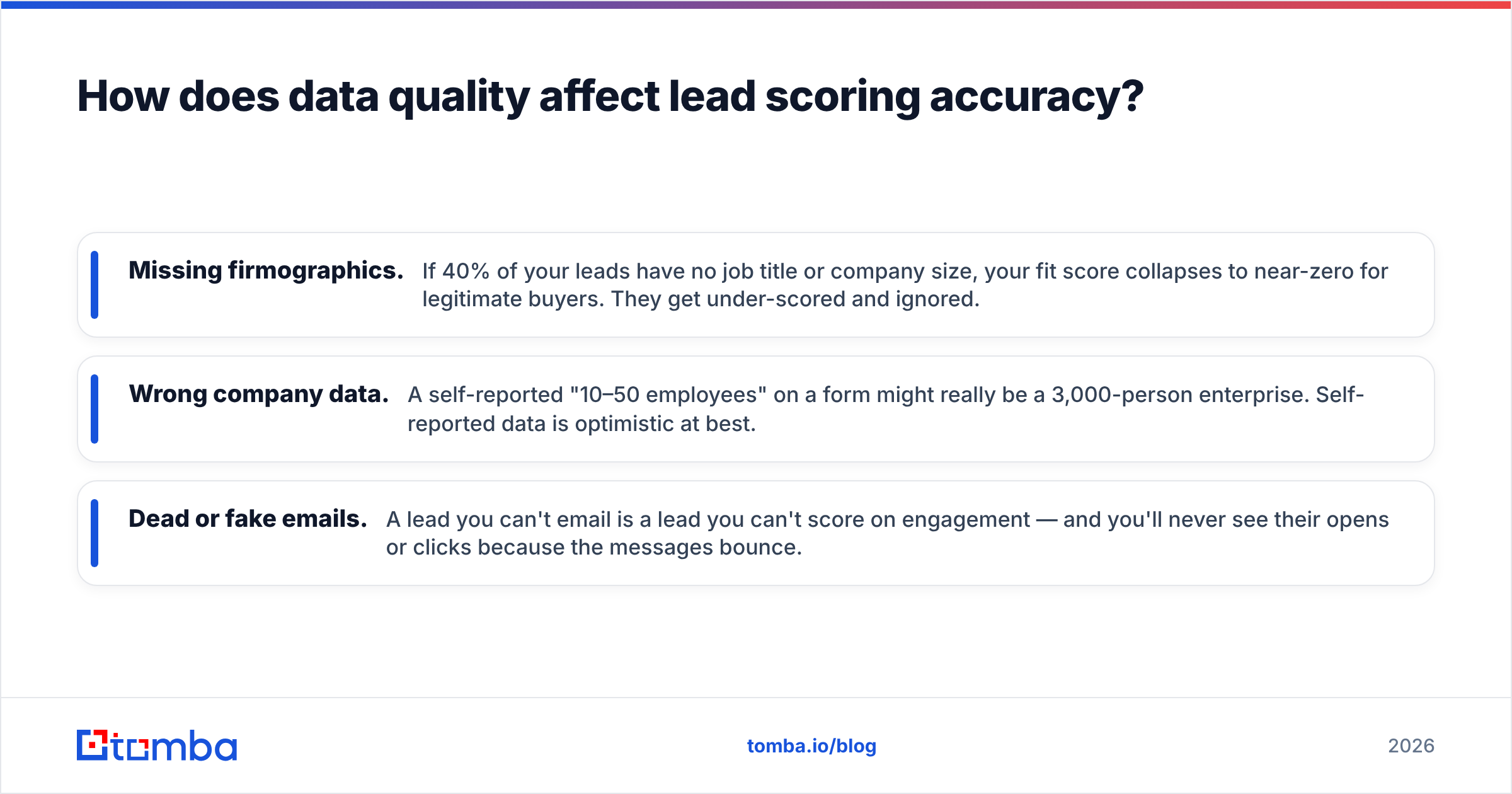
How does data quality affect lead scoring accuracy?#
Your scoring model is a calculator, and dirty data is the wrong numbers going in. You can design a perfect framework and still misrank every lead if the inputs are incomplete or false. This is the part vendors gloss over.
Three silent killers:
- Missing firmographics. If 40% of your leads have no job title or company size, your fit score collapses to near-zero for legitimate buyers. They get under-scored and ignored.
- Wrong company data. A self-reported "10–50 employees" on a form might really be a 3,000-person enterprise. Self-reported data is optimistic at best.
- Dead or fake emails. A lead you can't email is a lead you can't score on engagement — and you'll never see their opens or clicks because the messages bounce.
The fix is enrichment and verification before the lead enters the model. Append missing firmographics from a reliable source, and confirm the contact is reachable. Tools like data enrichment fill the firmographic gaps that power fit scoring, while an email verifier strips out the dead addresses that would otherwise pollute your intent signals. If you're sourcing net-new contacts to score, a domain search pulls verified addresses by company so your list starts clean instead of needing rescue later.

According to HubSpot's research on lead scoring, companies that align marketing and sales around a shared scoring definition see materially better conversion from MQL to opportunity — and that shared definition only holds if both teams trust the underlying data.
What are common B2B lead scoring mistakes?#
Most failed scoring programs die from the same handful of errors. Avoid these and you're ahead of the majority.
| Mistake | Why it hurts | Fix |
|---|---|---|
| No negative scoring | Tire-kickers rank as buyers | Subtract for poor fit & churn signals |
| Static weights forever | Market shifts, model rots | Recalibrate quarterly vs. closed-won |
| Scoring on vanity actions | Email opens ≠ buying intent | Weight bottom-funnel actions higher |
| Ignoring data decay | 6-month-old signals look fresh | Add time-based decay |
| One score for all products | Multi-product fit differs | Separate models per product line |
| Sales never sees the "why" | Reps distrust the number | Expose the score breakdown in CRM |
The biggest cultural mistake isn't on this table: building the model in marketing without sales in the room. If reps don't believe a "90" is real, they'll work the list in their own order and your scoring program becomes shelfware. Co-design the thresholds with the people who make the calls. Tie the model back to win rate so both teams are arguing about the same outcome.

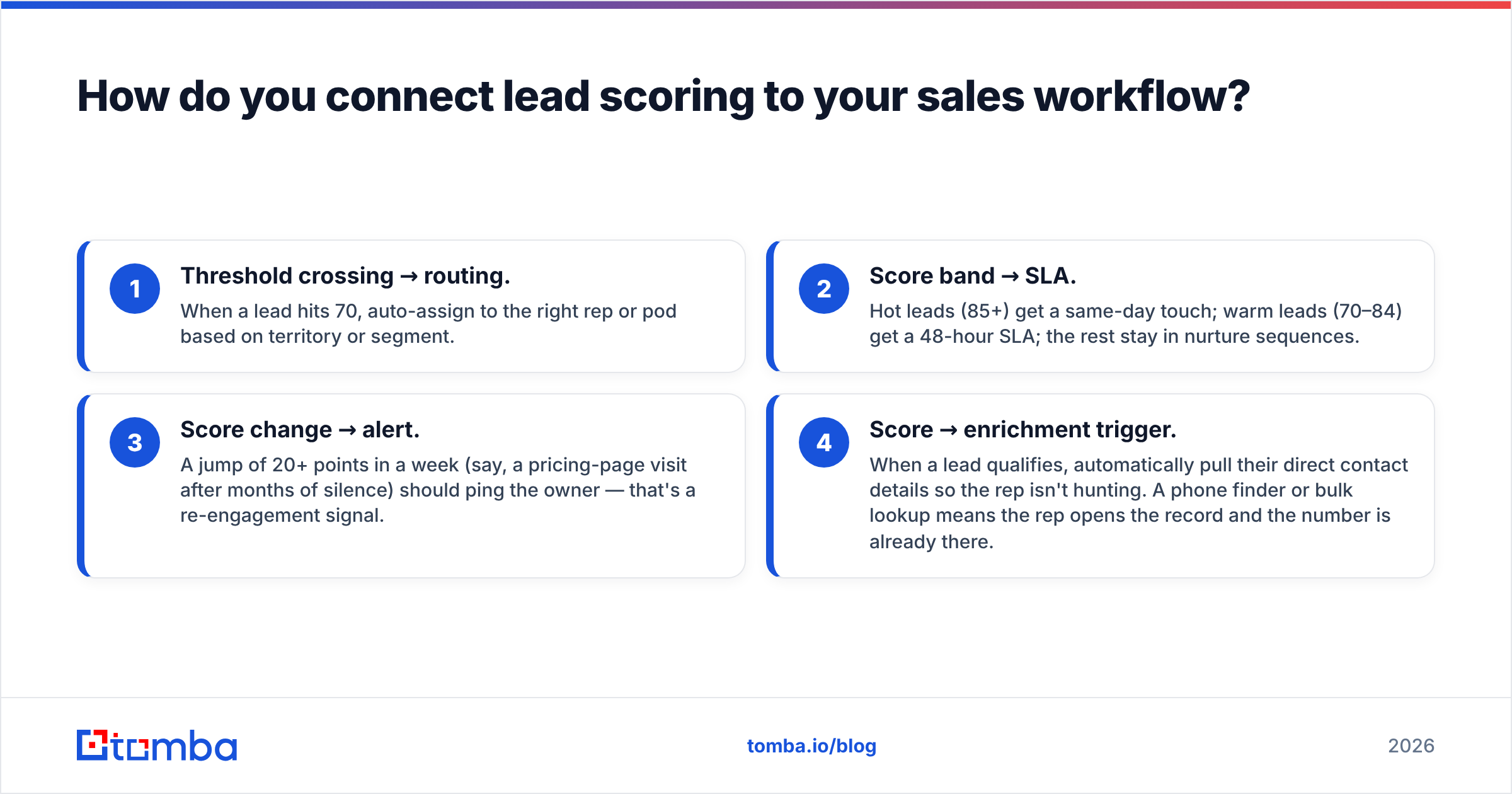
How do you connect lead scoring to your sales workflow?#
A score is useless until it triggers an action. The point of the number is routing, prioritization, and timing — not decoration in a CRM field.
Wire it up like this:
- Threshold crossing → routing. When a lead hits 70, auto-assign to the right rep or pod based on territory or segment.
- Score band → SLA. Hot leads (85+) get a same-day touch; warm leads (70–84) get a 48-hour SLA; the rest stay in nurture sequences.
- Score change → alert. A jump of 20+ points in a week (say, a pricing-page visit after months of silence) should ping the owner — that's a re-engagement signal.
- Score → enrichment trigger. When a lead qualifies, automatically pull their direct contact details so the rep isn't hunting. A phone finder or bulk lookup means the rep opens the record and the number is already there.
This is where scoring pays for itself. Reps stop spending the first 20 minutes of every call researching and start the day with a ranked, enriched, reachable queue. If you run high volume, a bulk email finder can enrich whole batches of newly-qualified leads on a schedule, and Tomba's integrations push that data straight into HubSpot, Salesforce, or Pipedrive where your scoring lives. For broader pipeline context, vendor docs like Salesforce's lead management guidance and analyst frameworks from Gartner are solid reference points when you formalize the process.
How often should you recalibrate your model?#
Recalibrate at least quarterly, and immediately after any major change to your ICP, pricing, or product line. A scoring model is a hypothesis about who buys, and hypotheses go stale.
The simplest recalibration loop: pull your last 90 days of closed-won and closed-lost deals, look at what scores they had when they entered the pipeline, and check whether high scores actually correlated with wins. If your 80+ leads closed at the same rate as your 50s, your weights are wrong. Adjust the attribute points up or down until the score genuinely separates winners from losers. Track the response rate on outreach to scored segments as an early signal between full recalibrations — it moves faster than closed-won and tells you when a band is decaying.
Predictive models technically retrain themselves, but they still need human review. An ML model trained on a biased history will faithfully reproduce that bias — if your reps historically ignored a profitable segment, the model learns to score it low. Audit the outputs, don't just trust them.
Putting it together#
B2B lead scoring works when three things line up: a model that reflects real buying behavior, data clean enough to feed it, and a workflow that turns scores into action. Skip any one and the program stalls — a great model on dirty data misranks everyone, and a perfect score nobody acts on changes nothing.
Start point-based, add negative scoring and decay, recalibrate against closed deals every quarter, and keep your fit data complete and your contacts verified. The fancy predictive layer can wait until you've earned it with clean history.
The data foundation is the part you can fix today. Before your next scoring pass, run your list through Tomba Email Finder to find and verify the professional emails behind your leads, fill the firmographic gaps that power fit scoring, and make sure every qualified lead is one your reps can actually reach. Clean inputs, accurate scores, full pipeline — start free with 25 searches a month, then scale on the Starter plan at $49/mo when scoring becomes part of your daily motion.
Ready to find emails that actually work?
Join 150,000+ professionals who stopped guessing and started sending. Free credits on signup — no credit card required.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author