B2B Data Intelligence in 2026: The Complete Buyer's Guide
Most B2B teams drown in data but starve for insight. Here's how B2B data intelligence actually works in 2026 — the layers, the tools, and the workflow that turns records into revenue.

TL;DR
- B2B data intelligence is the practice of collecting, cleaning, connecting, and acting on company and contact data so revenue teams target the right accounts at the right time.
- It is bigger than a contact list: it spans firmographics, technographics, intent signals, and the workflow that keeps all of it accurate.
- The biggest cost in 2026 is not buying data — it's decay. B2B records rot at roughly 25-30% per year, so freshness beats volume.
- A practical stack has four layers: sourcing, verification, enrichment, and activation. Skip any one and the others underperform.
- You can buy an all-in-one platform or assemble best-of-breed tools through an API. Most lean teams do better stitching focused tools than overpaying for bloated suites.
What is B2B data intelligence?#
B2B data intelligence is the discipline of turning raw business data — company records, contact details, technology footprints, and buying signals — into decisions your sales and marketing teams can act on. Think of it like a kitchen, not a pantry. Owning ingredients (a database) is not the same as running a kitchen that turns those ingredients into a meal on time, every time. Data intelligence is the kitchen: the people, tools, and recipes that convert stored data into served pipeline.
The "intelligence" part matters. A spreadsheet of 50,000 emails is data. Knowing which 400 of those contacts work at companies that just adopted a competitor's tool, hired a new VP of Sales, and opened your last three emails — that's intelligence. The gap between the two is where most revenue teams quietly lose money.
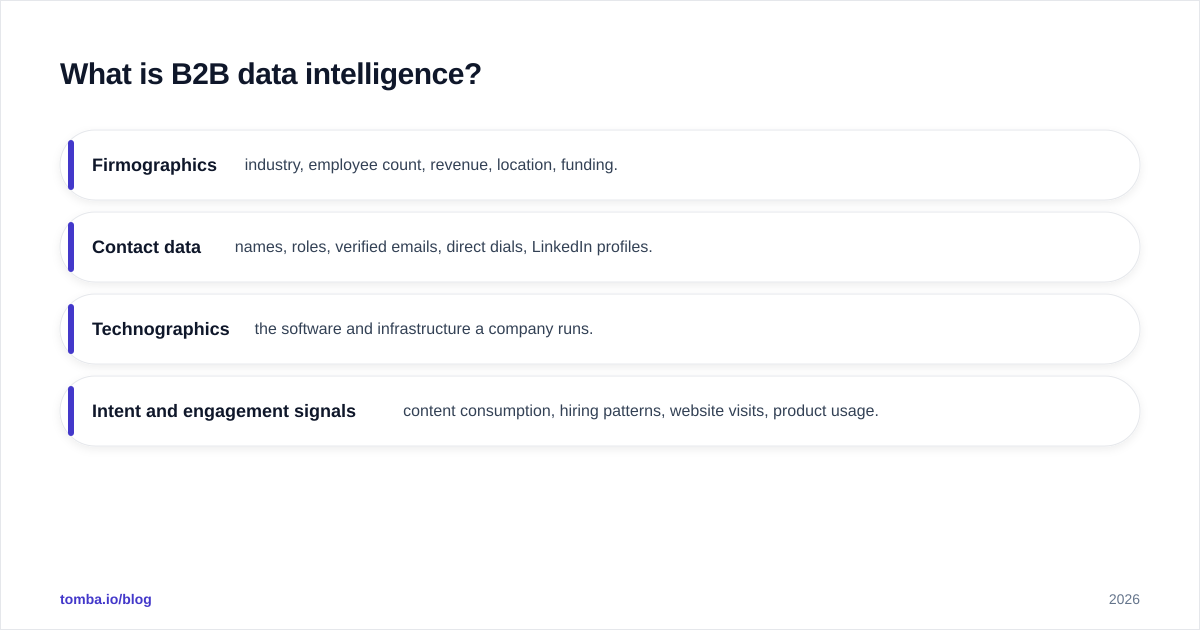
In technical terms, B2B data intelligence combines several data types into a single, queryable view of an account:
- Firmographics — industry, employee count, revenue, location, funding.
- Contact data — names, roles, verified emails, direct dials, LinkedIn profiles.
- Technographics — the software and infrastructure a company runs.
- Intent and engagement signals — content consumption, hiring patterns, website visits, product usage.
Why does B2B data intelligence matter in 2026?#
The short answer: targeting is now the entire game, and targeting runs on data quality. Outbound volume has been commoditized — everyone can send 2,000 emails a week. What separates teams that book meetings from teams that get filtered to spam is whether those emails reach real, relevant people. Gartner has repeatedly flagged poor data quality as a multi-million-dollar annual drag on the average organization, and that cost compounds in outbound where every bounce damages your sender reputation.
Three forces make this sharper in 2026:
- Decay accelerated. With elevated job mobility, contact records go stale faster than ever. An email you sourced in January may be dead by July.
- Deliverability got stricter. Mailbox providers tightened bulk-sender rules, so sending to unverified or risky addresses now actively suppresses your inbox placement.
- AI raised the floor and the bar. Everyone can generate decent copy now, so the differentiator moved upstream — to who you contact and why.

The teams winning right now treat data as a perishable asset, not a one-time purchase. They budget for continuous verification and re-data enrichment the same way they budget for ad spend.
What are the layers of a B2B data intelligence stack?#
A working stack has four layers, and each one feeds the next. If you picture a water system, sourcing is the reservoir, verification is the filtration plant, enrichment is the treatment that adds minerals, and activation is the tap in your kitchen. A leak at any stage means what comes out of the tap is undrinkable.
1. Sourcing. Where the raw records come from — a B2B database, domain search, public web pages, opt-in forms, or an email finder that locates addresses from a name and company. Sourcing quality is set by the provider's data sources and refresh cadence.
2. Verification. Before anything touches a CRM, it should pass through an email verifier and, ideally, a catch-all check. This layer answers one question: will this message bounce? Verification is the cheapest insurance you can buy against reputation damage.
3. Enrichment. Take a thin record (just an email) and fatten it — add title, company size, industry, location, and social profiles. Enrichment is what turns a list into a segmentable, prioritizable target set.
4. Activation. Push the clean, enriched, prioritized records into the tools where work happens: your CRM, your sequencer, your ad platform. Activation without the first three layers just automates the delivery of bad data faster.
Most failed "data projects" are really activation projects built on layers 1-3 that were never done. Fix the foundation first.
How is data intelligence different from data enrichment?#
People use the terms interchangeably, but they are not the same thing. Enrichment is a step; intelligence is the system. Enrichment answers "what else do we know about this contact?" Intelligence answers "which contacts should we work, in what order, with what message, right now?"
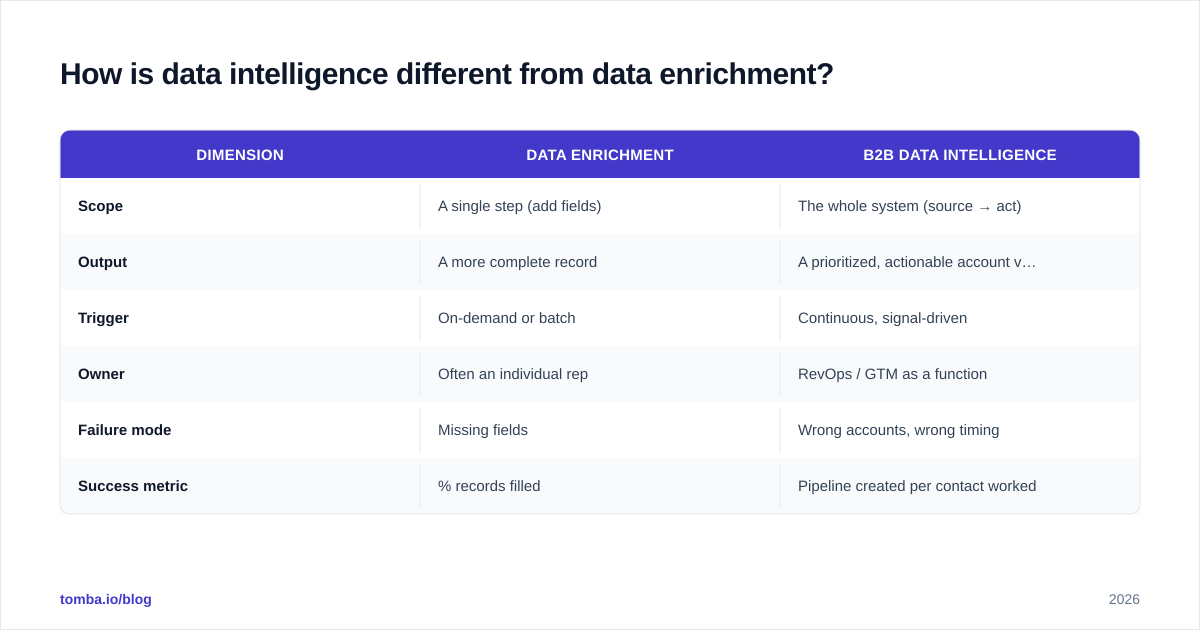
Here is the practical distinction:
| Dimension | Data enrichment | B2B data intelligence |
|---|---|---|
| Scope | A single step (add fields) | The whole system (source → act) |
| Output | A more complete record | A prioritized, actionable account view |
| Trigger | On-demand or batch | Continuous, signal-driven |
| Owner | Often an individual rep | RevOps / GTM as a function |
| Failure mode | Missing fields | Wrong accounts, wrong timing |
| Success metric | % records filled | Pipeline created per contact worked |
Enrichment is necessary but not sufficient. You can have a perfectly enriched record for someone who will never buy. Intelligence layers prioritization and timing on top so your reps spend their hours on the accounts most likely to convert.
How do you choose a B2B data intelligence platform?#
Start by being honest about whether you need a platform at all, or a few sharp tools connected through an API. The all-in-one suites (the 6sense / Demandbase /
ZoomInfo tier) are powerful but priced for enterprise and often sold on annual contracts that punish small teams. Best-of-breed assembly — a strong email finder plus a verifier plus an enrichment endpoint — covers most mid-market needs at a fraction of the cost.
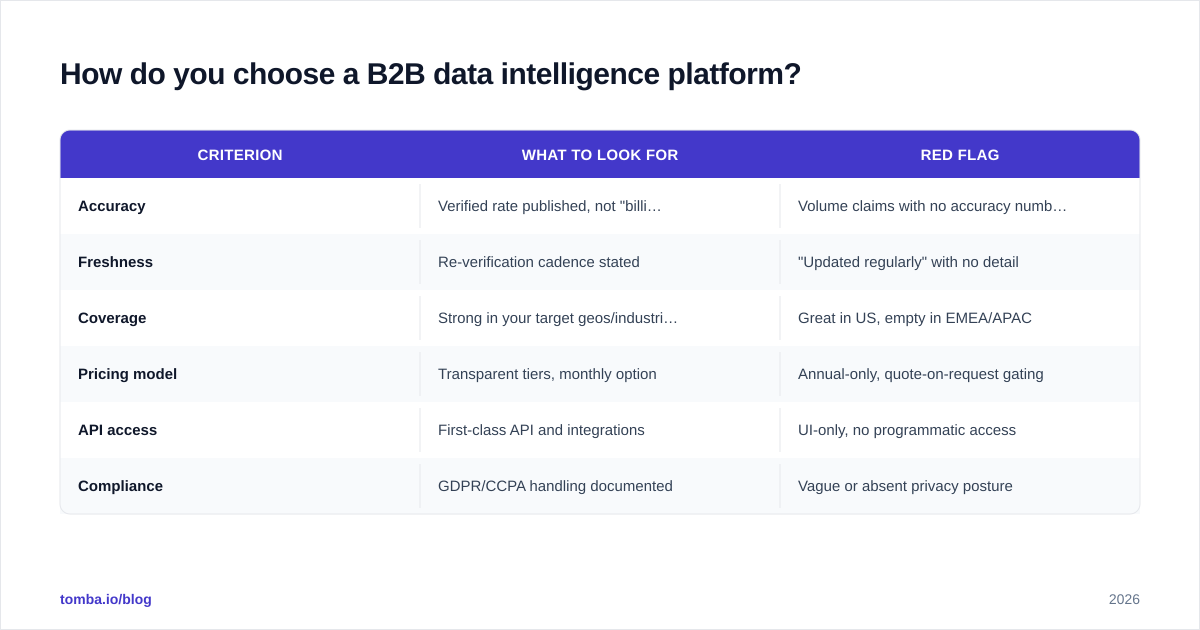
Evaluate every option against these criteria, not the demo dazzle:
| Criterion | What to look for | Red flag |
|---|---|---|
| Accuracy | Verified rate published, not "billions of contacts" | Volume claims with no accuracy number |
| Freshness | Re-verification cadence stated | "Updated regularly" with no detail |
| Coverage | Strong in your target geos/industries | Great in US, empty in EMEA/APAC |
| Pricing model | Transparent tiers, monthly option | Annual-only, quote-on-request gating |
| API access | First-class API and integrations | UI-only, no programmatic access |
| Compliance | GDPR/CCPA handling documented | Vague or absent privacy posture |
Cross-check vendor claims on independent review sites like G2 and read the verified-buyer reviews, not the vendor's own case studies. Pay special attention to comments about refunds and credit policies — that's where data-quality complaints surface first.

On pricing, anchor your budget to a real workflow. If you find 1,000 contacts a month, you don't need an enterprise seat — you need enough credits to find, verify, and enrich those 1,000 records reliably. Tomba, for example, runs a free tier (25 searches/month) and then paid plans from $49/month (Starter), $99/month (Growth), and $249/month (Pro), with Enterprise available for higher-volume needs. Match the tier to your monthly contact velocity, not to an aspirational headcount.
How do you build a data intelligence workflow that lasts?#
The goal is a loop, not a project. A one-time data buy is a snapshot of a moving target; a workflow keeps the target in focus. Here is a process that holds up for most outbound and ABM teams.
- Define the ICP precisely. Industry, size band, geography, and the technographic or intent signals that mark a good fit. Vague ICPs produce vague lists.
- Source against the ICP. Use domain search to map decision-makers at target accounts, or an email finder to locate specific people you've identified.
- Verify before storage. Route every address through verification. Drop hard bounces, flag risky and catch-all addresses for a lighter-touch channel.
- Enrich for segmentation. Add the fields you'll actually use to prioritize and personalize. Don't enrich fields nobody will ever query.
- Activate by priority. Push to your CRM and sequencer with a clear tier order, so reps work the best-fit accounts first.
- Re-verify on a cycle. Set a recurring job — quarterly at minimum — to re-check and refresh records. This is the step almost everyone skips, and it's the one that quietly determines whether the whole system stays useful.
The compounding effect is real: a team that re-verifies quarterly will, within a year, dramatically outperform a team that bought a "bigger" list once and let it rot.

What are the most common B2B data mistakes?#
- Chasing volume over accuracy. A 10,000-contact list that's 60% deliverable is worse than a 2,000-contact list that's 97% deliverable — because the bad list also wrecks your inbox placement for the good contacts.
- Skipping verification to save credits. This is false economy. The cost of a verification credit is trivial next to the cost of a damaged sending domain.
- Treating catch-all domains as either all-good or all-bad. They need their own handling. A dedicated catch-all verifier tells you which catch-all addresses are worth the risk.
- No re-verification cadence. Data bought in Q1 and used untouched in Q4 is a different, worse dataset by then.
- Buying intelligence you can't activate. If your CRM and sequencer can't ingest the signals, the signals are decorative. Confirm your integrations before you buy.
- Ignoring compliance. GDPR and CCPA aren't optional. Document where data comes from and how you handle deletion requests, or you're buying liability with your leads.
How does B2B data intelligence fit with the rest of your GTM stack?#
Data intelligence is the input layer for nearly everything else in go-to-market. Your revenue operations function owns the definitions and the hygiene rules. Your CRM stores the activated records. Your sequencer and ad platforms consume them. The cleaner the input, the better every downstream tool performs — there is no amount of clever copywriting or sequencing that rescues a list pointed at the wrong people.
This is why mature teams put RevOps, not individual reps, in charge of the data layer. When each rep sources and "cleans" their own data, you get fifty inconsistent definitions of a qualified account and zero shared hygiene. Centralizing the intelligence layer — even lightly, with shared tools and a shared verification standard — produces a single source of truth that every team can trust. For more on how providers source and maintain this data, vendor documentation like Salesforce's data management guidance and HubSpot's data quality resources are worth reading; see the HubSpot and Salesforce knowledge bases for platform-specific practices.
Where should a lean team start?#
Don't boil the ocean. Start with the layer that's leaking the most. For most teams, that's verification — they're sitting on a CRM full of decayed records that's actively hurting deliverability. Run a one-time verification pass, quantify the bounce risk you just removed, and use that win to justify building the full loop.
From there, add sourcing and enrichment that plug into the same workflow, and set your recurring re-verification job before you do anything else. The discipline of the cycle is worth more than any single tool choice.
Ready to build a cleaner data layer?#
If you want a fast, accurate place to start sourcing and verifying contacts, the Tomba Email Finder is built exactly for this workflow — find professional email addresses by name, domain, or company, then verify them before they ever touch your CRM. Pair it with Tomba's verifier, domain search, and enrichment endpoints through one API, and you have the four-layer stack from this guide in a single toolkit. Start on the free tier, prove the lift on a real list, and scale the plan to your monthly contact velocity from there. Clean data isn't a nice-to-have in 2026 — it's the difference between pipeline and spam folder.
Ready to find emails that actually work?
Join 150,000+ professionals who stopped guessing and started sending. Free credits on signup — no credit card required.
Get the Tomba newsletter
Practical outbound tactics and product updates — once every two weeks.
About the author